
1 Introduction
Studies in comparative syntax have shown that natural languages vary in the strategies adopted in conveying discourse properties (Rizzi 1997; 2004; Endo 2007; Abels 2012; Shlonsky 2015). A strategy is the displacement of constituents bearing relevant informational properties (since Chomsky 1977), such as interrogative or focalized elements. This type of displacement is widely adopted among natural languages, and well documented in Romance or Germanic (Ross 1967; Cinque 1990; Cecchetto 2000; Ott 2014).1
We refer to displacement of syntactic elements as a phenomenon involving a dependency relation whereby a constituent is interpreted simultaneously in two different positions (Belletti 2018). Let us consider the Italian declarative in example (1), in which lo studente ‘the student’ and il libro ‘the book’ are generated respectively to the left and to the right of a lexical verb and interpreted as the subject and the object of the verb leggere ‘to read’, representative of the canonical SVO (subject, verb, object) word order of Italian (Dryer & Haspelmath 2013).
- (1)
- Lo
- the
- studente
- student.m.sg
- ha
- has
- letto
- read
- il
- the
- libro.
- book.3.m.sg
- ‘The student has read the book’
If one constituent must be displaced for discourse reasons, the structure and/or the word order may change. In Italian, for example, relative clauses (Alexiadou et al. 2000; Andrews 2007) show the relevant relativized element (the subject in (2)a; the object in (2)b) located at the beginning of the syntactic structure, followed by a functional element, a complementizer, che ‘that’.
- (2)
- Relative Clauses
- a.
- Lo
- the
- studente
- student.m.sg
- che < lo studente >
- that
- ha
- has
- letto
- read
- il
- the
- libro.
- book.m.sg
- ‘the student that read the book’
- b.
- Il
- the
- libro
- book.m.sg
- che
- that
- lo
- the
- studente
- student.m.sg
- ha
- has
- letto < il libro >.
- read.
- ‘The book that the the student has read’
The relativized element moves from its locus of generation, marked in angle brackets in the examples (2), to a landing site higher than the complementizer che ‘that’. The displaced elements in (2) are now interpreted in two positions: the position in which the constituents are phonetically overt and the “copies” of their argumental structure. The dependency created by the source position and the landing site has been object of study by a wealth of literature of parsing (Rizzi 1990; 2004; Gibson 1998; Gibson & Warren 2004; Lewis & Vasishth 2005; Friedmann et al. 2009; Villata et al. 2016 inter alia).
The current study addresses a particular type of syntactic reordering discussed in the literature under the label of clefts (Jespersen 1937; Lambrecht 2001; Haegeman et al. 2015; Belletti 2015). Similar to relative clauses, clefts involve the movement of a constituent to the very beginning of the structure preceding the complementizer che ‘that’. What distinguishes clefts from relative clauses is the presence of a copula in front of the displaced constituent and the semantics conveyed by the dislocated element, which expresses, among other properties, focalisation, a further dimension of semantics and discourse of a syntactic constituent (Kiss 1992; Rizzi 1997; Beck 2006; Bianchi et al. 2015). Another difference between clefts and relative clauses is that clefts are propositions and relative clauses are not. Examples from Italian are provided in (3).
- (3)
- Cleft clauses
- a.
- È
- Is
- lo
- the
- studente
- student.m.sg
- che < lo studente >
- that
- ha
- has
- letto
- read
- il
- the
- libro.
- book.m.sg
- ‘It is the student that has read the book’
- b.
- È
- Is
- il
- the
- libro
- book.m.sg
- che
- that
- lo
- the
- student
- student.m.sg
- ha
- has
- letto < il libro >.
- read.
- ‘It is the book that the student has read’
Cleft structures are single propositions with biclausal syntax (that is, they exhibit two inflected verbs), containing a syntactic gap linked to the clefted element in a long-distance dependency.2 In (3), the clefted element has been displaced to a higher clause, preceded by a copula element (and its impersonal subject when required, e.g. French, English) and followed by a complementizer. Different types of syntactic constituents can be clefted in these structures, such as subjects (e.g. lo studente ‘the student’ as in ((3)a)), objects (as il libro ‘the book’ as ((3)b)), and non-core elements/adjuncts (e.g. temporal and locatives items such as, for example, in biblioteca ‘in the library’ or l’anno scorso ‘last year’). We will refer to them as subject, object and adjunct/adverbial clefts throughout this paper. From a syntactic point of view, clefts, together with relatives, belong to the set of structures involving long-distance dependency relations. The cross-linguistic and intra-linguistic availability and acceptability of these structures depends on many factors (Rizzi 1990, 2013; Gibson 1998). We study here the predictions of an intervention theory of locality (Rizzi 2004; Friedmann et al. 2009).
In a nutshell, the intervention theory of locality says that a long-distance dependency between two elements in a sentence is difficult, and sometimes impossible, if a similar element structurally intervenes between the base-generation position and the landing site. For example, in object-oriented relative/cleft clauses, as in ((2)b) and ((3)b), the relativized/clefted DP object il libro ‘the book’ crosses a similar element (an intervener) in syntactic terms, namely the DP subject lo studente ‘the student’ generated higher, while in subject relative/cleft clauses, as in ((2)a) and ((3)a), the relativized/clefted subject does not cross any relevant intervener.
According to the intervention theory of locality, the crucial property is not the amount of material that can be considered as intervening, but rather its quality. Ungrammatical structures or slower parsing effects arise, if the ultimate landing site and the intervener share relevant features relevant for locality (see Rizzi 1990 for a first theoretical account). Intervention does not block the movement in adult grammar in cleft/relative structures, but these long-distance relations are difficult for specific populations of speakers, such as early grammars and language pathology (Rizzi 1990; 2004; 2013; Grillo 2008; Friedmann et al. 2009; Martini et al. 2020). And even in adult grammar, despite their grammaticality, previous studies show that quantitative differences can be observed in structures with or without intervention (Samo & Merlo 2019).
In this work, we aim to add a quantitative dimension to the established qualitative descriptions of intervention effects in cleft structures, adopting the tools of Quantitative Computational Syntax (Merlo 2016, Gulordava & Merlo 2020). Using large-scale resources and simple computational models, we verify the quantitative predictions of linguistic proposals. This methodology assumes that underlying grammatical properties surface quantitatively, once independent influences of use are properly factored out. The guiding general hypothesis is that the specific properties triggering ungrammaticality in a given environment will still be disfavoured when a structure is grammatical in other environments (Bresnan et al. 2001).
We investigate three languages in which cleft structures naturally occur with different productivity (French, Italian and English) in treebanks syntactically annotated under the guidelines of Universal Dependencies (Zeman et al. 2020). We observe variation in the quantitative properties of clefts. This result provides further insights into the nature of grammatical structures extracted from corpora, and the principles that govern preferences and dispreference of specific subtypes of reorderings of constituents.
Our methodology requires comparing the distribution of the features under investigation in those contexts where no intervention effects occur to the distributions of the same features in those contexts where intervention effects occur. Plausible no intervention contexts are “canonical” orders, as will be discussed in detail in sections 3 and 4. In these sections, we present the formal steps to quantify intervention effects and elaborate predictive counts. Section 5 will present the evidence drawn from corpora to be compared with the expected results. Section 6 shall present a further puzzle given by non-argumental clefts. Finally, sections 7 and 8 discuss and conclude.
2 Cleft structures and asymmetries between subject and non-subject
A wealth of literature has investigated the nature of cleft structures and many descriptions, typologies and interpretations of their properties have been proposed (Prince 1978; Meinunger 1998; Roggia 2008; Dufter 2009; Reeve 2012; Frascarelli & Ramaglia 2013; Haegeman et al. 2015; Belletti 2015; Karssenberg & Lahousse 2018; De Cesare & Garassino 2018; Chesi & Canal 2019). In this work, we adopt the label ‘clefts’ to investigate the it-clefts shown in example (3). A large body of literature assumes that the clefted constituent in cleft structure has been extracted from a lower clause (Kiss 1998), via A’-movement (but see Doetjes et al. 2004 for discussion), and may encode different properties of information-structures such as a typology of foci (Belletti 2015) or (given) topics (Doetjes et al. 2004; Karssenberg 2017; 2018; Karssenberg & Lahousse 2018). Cross-linguistic studies have shown that natural languages allowing clefts vary in the frequency of usage of these structure (Roggia 2008; Dufter 2009). For example, clefts represent a preferred answer strategy in French for questions on a specific constituent (Belletti 2010). Clefts also represent interesting loci of micro-variation: it has been shown that Swiss German speakers produce a higher frequency of cleft structures than German speakers from Germany, in specific registers (Stark 2014).
Cleft sentences exhibit a well-documented asymmetry between subject and non-subject clefts. Experimental studies have shown that there is a tendency for subject clefts to be easier to parse than object clefts and many grammatical accounts have proposed that these two types of clefts have slightly different syntactic and discourse properties (Bever 1974; Dick et al. 2004; Lobo et al. 2019; Chesi & Canal 2019 and reference therein).
We discuss a simplified theory, compatible with several analyses, where no distinctions are made between focus and topic positions (see, however, Belletti 2015 for a detailed cartographic derivation of cleft structures). This necessary simplification is due to the nature of our data, as we cannot account for any discourse features (i.e. topics, foci) of the naturally occurring examples extracted from syntactically annotated treebanks. We quantify asymmetries in grammatical clauses between subject-oriented clefts and object-oriented clefts (Friedmann et al. 2009; Skopeteas & Fanselow 2009; Dick et al. 2004; Aravind et al. 2018; Lobo et al. 2019). The simplified derivations consider only the movement of the argument to a higher unlabelled position, as given in (4)–(5). The crucial difference between the two derivations is clear: in (4), no intervention is at play, while in (5), the object has to cross the subject to reach the relevant position.
| (4) | Subject Clefts | |||||||
| [SpecTP | C’est | [ | S | [IP | <S> | V | O]]] | |
| (5) | Object clefts | |||||||
| [SpecTP | C’est | [ | O | [IP | S | V | <O>]]] | |
In configurations of the type in (5), objects cross subjects in grammatical sentences on their way to a dedicated functional projection. The grammaticality in A’-movement is given by the fact that the moved element and the intervener are not in an identity relation (the features of the moved element and those of the intervener do not fully match), since the displaced constituent bears discourse features (e.g., +Topic, +Focus, etc.).3
The intervention-based account we investigate here is centred on representational theories of locality (Friedmann et al. 2009; Belletti et al. 2012; Belletti 2015; 2018; Martini et al. 2020), in which only morpho-syntactic features (such as number or person, as it will discussed in detail in section 3 and subsection 4.1) play a role.
The main reason for this choice is the nature of our data. Its syntactic annotation, based on Universal Dependencies (Zeman et al. 2020), limits our investigation to a grammatical theory. We defer the direct investigation of those other theories, either memory-based or similarity-based, that account for processing effects through a set of features (e.g., animacy, definiteness, etc.) that in our annotations would be unrestricted or unattainable (Gibson 1998; Gordon et al. 2001; Gibson 1998; Gibson & Warren 2004; Warren & Gibson 2002; Lewis & Vasishth 2005).
Memory-based accounts explain the asymmetry between subjects and objects in clefts or relative clauses as deriving from a different amount of material stored in memory (Gibson 1998; Gordon et al. 2001; Lewis & Vasishth 2005) or from the joint costs of integrating them within the parsing structure being built (Gibson 1998; Gibson & Warren 2004; Warren & Gibson 2002). The structural integration costs are based on an accessibility scale of referentiality (Ariel 1990).
Similarity-based processing accounts argue that a limitation for memory is due to similarity-based interference (Gordon et al. 2001; 2002; 2004; 2006). This account only partially overlaps with syntactic locality (Rizzi 1990; Friedmann et al. 2009). Similarity-based processing approaches are defined on (morpho-)syntactic features (type, person, number, gender, case), but, unlike grammatical accounts, also on extra-syntactic features, for example, animacy, and assume that all features equally contribute to memory interference. We cannot easily retrieve the distribution of features such as animacy or referentiality from our data in a simple and reliable way.
Our goal in this paper is to detect whether we can also observe asymmetries concerning distributions and distribution of features between (4) and (5) in grammatical clauses extracted from corpora.
3 Quantifying intervention effects in grammatical clefts
In this work, we assume that underlying grammatical properties surface quantitatively (Merlo 2016, Gulordava & Merlo 2020). Our methodology requires comparing the distribution of the features under investigation in those contexts where no intervention effects occur to the distributions of the same features in those contexts where intervention effects occur. In Samo & Merlo (2019), a comparison of the theoretically expected and observed counts of features of object relative clauses, like the structure in (2) in Italian and English, reveals that a set of morpho-syntactic features plays a role in the syntactic computation of locality. An important aspect in verifying the intervention-based explanation of locality effects, then, will be determining if quantitative effects are also observed in cleft structures.
Based on the findings in the theoretical and experimental literature, we formulate a first general hypothesis:
H: if the clefted element of a grammatical cleft structure is similar to an intervener, then this type of cleft shall surface less frequently than other clefts in which the two elements are dissimilar or no intervention is at play (e.g. subject clefts).
This quantitative prediction will be made more specific later in the section. It is made explicit here to allow us to illustrate which objects of our counts we need to define precisely. In this work, the core notions are the concept of similarity, central to the notion of intervention, the representations of the elements (subjects and objects) whose similarity needs to be calculated, and the linking hypothesis that connects these definitions to the counts. We provide here some definitions that will be needed to formulate our quantitative expectations.
Features The head of the cleft and the intervener are represented as vectors of movement-relevant features. Features are (type:value) pairs, such as (gender: feminine).
Similarity The head of the cleft and the intervener are similar if their features match.
Feature match A feature match, matchf (C,I), is true iff, for a given feature f, the head of the cleft C and the intervener I are instantiated and have the same value. If one of the two elements being compared, the head of the cleft C and the intervener I or both are not instantiated, then matchf (C,I) is false.4
Linking hypothesis A stronger intervener creates greater inacceptability and hence surfaces less often in a corpus in a match configuration. An intervener strength depends on the number of matching features.
In this work, we make use of observational data provided by corpora, and operate on counts. We refer here to the notion of observed counts and expected counts.
Observed counts Observed counts are the counts in the corpus.
Expected counts Expected counts are the counts of the features that we expect based on their distribution in settings where intervention is not at play and, therefore, they do not interact with each other. In other words, the expected counts are the counts we would expect given the prior joint probability of the features, the probability to co-occur without intervention.
We build our predictions on the distribution of a series of morpho-syntactic features on structures where no intervention has taken place, such as declarative (“canonical”) orders, such as the Italian SVO sentence given in (1). Specifically, an object-oriented cleft clause brings into play the object of the verb and its features, the noun phrase that is being cleft, and the subject of the sentence and its features, the intervener. Precisely, let  be the counts of a feature value in a subject and object pair in a sample of size S. Let T be the total number of observed counts. Then, the expected counts of the subject and object pair feature value occurring in a sentence are calculated as
be the counts of a feature value in a subject and object pair in a sample of size S. Let T be the total number of observed counts. Then, the expected counts of the subject and object pair feature value occurring in a sentence are calculated as 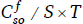 .
.
Following Merlo (2016) and related works, we use corpus counts in the spirit of the computational quantitative syntax framework: differentials in observed and expected counts are the expression of underlying grammatical properties. In this respect, our quantitative hypotheses below are to be contrasted to an H0 hypothesis that would predict that grammatical properties are uncorrelated to observed counts in a corpus, because corpus counts are effects of usage, while grammar makes no predictions about them, and as such there is no expectation of distribution of counts beyond the observed ones.
We can now formulate our specific hypotheses. The first hypothesis is directly derived from the discourse asymmetries discussed in previous sections. No intervener blocks the movement of the subject in subject clefts, while a subject acts as intervener for the object in object cleft configurations.5 This asymmetry (no invervention, intervention) should be reflected in different raw frequencies. Therefore, we expect that the counts of the observed subject clefts in UD treebanks should be greater than the counts of object clefts, in the three languages under investigation.
H1: The raw counts of subject clefts in UD treebanks are expected to be greater than the raw counts of object clefts.
A second hypothesis concentrates on the relation between expected and observed counts. Our expected counts are estimated on syntactic structures where apparently no movement has occurred (such as canonical, non-reordered SVO structures). Comparing these expected counts to observed counts, we detect how movement, matching or mismatching configurations and locality effects interact with frequencies. Therefore, we expect to find trends between the distribution of frequency of clefts and the number of matches, with mismatching configurations to be preferred to matching configuration in object cleft environments.
H2: In object clefts, the observed counts of feature-matching configurations are expected to be lower than their expected counts, and the observed counts of mismatching configurations should be equal or higher than their expected counts.
The relation between expected and observed counts on subject clefts represents control group for H2. Despite being a construction where a word order displacement has been triggered, no intervention takes place in subject cleft environments, since the subject does not cross similar elements towards the targeted peripheral positions. We therefore predict that the observed counts of subject clefts will not differ from the expected counts.
H3: In subject clefts, the observed counts of both feature-matching and mismatching configurations are expected to be approximately equal to their expected counts.
These quantitative hypotheses will be tested on corpora. In the next section, we present the materials for the investigation of the distribution of a subset of features in canonical orders which will represent the basis for the calculation of the expected counts in clefts. These counts are estimated based on the observed counts of subject and object co-occurrences in canonically-ordered SVO constructions.
4 Collecting expected counts: feature distributions in canonical orders in UD treebanks
To validate our hypotheses, we must establish the expected counts of morpho-syntactic features in a language based on the distribution of the features in canonical/unreordered environments. In subsections 4.1 and 4.2, we present the featural properties in the languages under investigation and their values, while in subsection 4.3, we introduce the materials and methods for the calculation of the expected counts.
4.1 Features and intervention effects
To detect the nature of the intervener and the material of the long-distance dependency, we choose to investigate the morpho-syntactic features of type, number, person and gender.
The notion of type goes back to the core formulation of intervention locality theory and has been shown to be active in the acquisition of object relative clauses (Rizzi 1990; Friedmann et al. 2009). This feature has two values: an element can be a Head like pronominal elements (e.g. elle ‘she’ in French) or maximal projections (e.g. la présidente ‘the president’ in French) which we refer as xp. Secondly, the person feature (1st, 2nd, 3rd) was early noticed (Bever 1974) to be a mitigator in parsing difficult structures involving A’-movement (Chesi & Canal 2019). The third feature under investigation is the morpho-syntactic feature of number (singular or plural), which has been well studied because it is strictly related to the richness of the verbal morphological system (Bentea 2015). Finally, the manipulation of the two-valued gender feature (feminine, masculine) shows interesting results in language acquisition studies in those languages where gender is morpho-syntactically realized (Belletti et al. 2012).
To detect the asymmetries formulated in the hypotheses and verify their cross-linguistic validity, we analyze the patterns of feature co-occurrence in a set of languages showing variation in the realization of these morpho-syntactic features: Italian, in which the four features of interest have overt realizations; French, in which the same morpho-syntactic features are partially not audible (see Bentea 2015); English it-cleft constructions, in which only the three features of type, person and number can be considered.
4.2 Feature values
The values of type are xp (Nouns, proper nouns) and heads (pronouns); the feature person has three values: 1st, 2nd and 3rd person; the feature number can take two values: singular and plural; finally, the feature gender also distinguishes between two values, feminine and masculine. For undetermined features that we cannot automatically retrieve from syntactically annotated corpora, we will use the value u. In Figure 1, we show some examples of cleft clauses with these features in the three languages under investigation. We select these features to explore several dimensions of variation.

Examples of subject cleft clauses in several featural configurations in the three languages under investigation (XP = maximal projection, 3rd = 3rd person, Sing = singular, Fem = Feminine, Masc = Masculine).
4.3 Calculating Expected counts
As presented in section 3, hypotheses H2 and H3 follow a common schema that requires calculating the observed counts of a feature in the corpus and compare it to the counts we would expect if intervention was not at play. The collection of counts is done on syntactically annotated corpora, presented in subsection 4.3.1.
4.3.1 Materials & Methods
To establish a priori expected counts, we first need to observe the distribution of features of subjects and objects where no intervention is at play. Declarative canonical sentences showing subjects and objects provide the right configuration. With the term canonical, we refer to the standard ordering of constituents in which informational properties are clause-related or about the subject (Rizzi 2015, Belletti & Rizzi 2017). In the three languages under investigation, the order SVO of the core elements (Subject (S), Verb (V) and Object (O)) is canonical.6
Our query retrieves all the occurrences of subjects preceding objects according to the different combinations of features and values in a treebank. The status of null subjects (NS) (Rizzi 1982) in Italian is not investigated. This choice is due to the fact that we need to detect SVO structures where both elements are phonetically overt. Indeed, the search for sentences with null subject will alter the results: as early noted by Grimshaw & Samek-Lodovici (1998: 195), the antecedent of pro, the syntactic element filling the subject position (Rizzi 2015), has a topic discourse status. Similarly, Frascarelli suggests that “[a] thematic NS is a pronominal variable, the features of which are valued (i.e., ‘copied through matching’) by the local Aboutness-Shift Topic” (Frascarelli 2007: 694). See also (Frascarelli & Hinterhölzl 2007; Bianchi & Frascarelli 2010). Moreover, the lack of a subject (and a subsequent subject position) will not automatically disambiguate the discourse status of the sentence (e.g. subject relative or imperative clauses).7
Our material is extracted from syntactically annotated treebanks for French, Italian and English, following the guidelines of Universal Dependencies annotation scheme (Zeman et al. 2020). We choose Universal Dependencies (henceforth, UD) because the uniformity of UD annotation across languages makes a comparative investigation possible. For every language, we sampled the most uniform treebanks in terms of variety of genres and the biggest in terms of size of trees/tokens. The Italian treebank is the Isdt 2.5 (Bosco et al. 2014; 14167 trees/298343 tokens; legal, news, wiki); the French treebank is the Gsd 2.5 (Guillaume et al. 2019; 16342 trees/400396 tokens; blog, news, reviews, wiki); finally, the English treebank is the the Gum 2.6 (Zeldes 2017; 5961 trees/113374 tokens; academic, fiction, nonfiction, news, spoken, web, wiki). All the materials are extracted with the Grew-match tool maintained by Inria in Nancy (http://match.grew.fr). The query looked for a variable x annotated with a combination of morpho-syntactic features (type, person, number, gender) and a subject dependency, a variable y annotated with a combination of morpho-features (type, person, number, gender) and the syntactic label object, so that x precedes y.
Table 1 shows some examples of naturally occurring clauses in English extracted from the morpho-syntactically annotated corpora, presented in the sub-section 4.3.1. We work at a morpho-syntactic level and not at the interpretative level. For example, we coded French il expletives as head, sing, 3rd, masc.
Matching configurations. The examples are naturally occurring clauses extracted from the UD corpora. tM = Type feature, match (1) or mismatch (0), nM = Number, match (1) or mismatch (0), pM = person feature, match (1) or mismatch (0).
| tM | nM | pM | subject | verb | object |
|---|---|---|---|---|---|
| 1 | 1 | 1 | A girl | raises | her hand. |
| XP, Sing, 3rd | XP, Sing, 3rd | ||||
| 1 | 0 | 1 | They | accepted | it. |
| Head, Plur, 3rd | Head, Sing, 3rd | ||||
| 0 | 1 | 0 | I highly | recommend | his shop. |
| Head, Sing, 1st | XP, Sing, 3rd | ||||
| 0 | 0 | 0 | My parents do not | like | me. |
| XP, Plur, 3rd | Head, Sing, 1st. | ||||
A manual analysis of the extracted examples has been conducted to provide high-quality counts of the investigated data. From a technical point of view, the annotations in French and Italian share one issue in automatically retrieving the combination of features. In the investigated treebanks, pronouns of first and second person (both singular and plural) are not annotated for gender and the analysis could not infer any further property from the given context. So these counts are imputed using the notion of fractional counts: the observed counts of these underspecified features are split in equal parts between masculine and feminine. For English, the automatic retrieval of the morphological properties of the second personal pronoun you was complicated by its underspecification for number. We split the counts in equal parts into the two morphological features of singular and plural. Analogously to the French impersonal pronoun il, we only look at the real morpho-syntactic realization of the feature and therefore we will not provide a further coding for you as impersonal element.8
4.3.2 Distribution of features in SVO and expected counts
Table 2 offers a summarised view of the data, where matches is a random variable that counts how many features match, thus collapsing the actual value of the matching feature. As it can be observed, the proportions are quite similar in Italian and French. Mismatching configurations (0 matches) of overt subjects and objects are extremely rare in both French and Italian (0.01%). On the other hand, English has only three features and different proportions and different aggregated counts. The nature of the investigated corpus and a smaller set of combinations of features provide slightly different results in comparison with the two Romance languages. However, mismatching configurations are still the least frequent (0.11%). The data presented in this subsection represent the basis for the calculation of the expected distributions of features and matching configurations for subject and object clefts, since they represent the expected proportions of cases of a subject and an object occurring with a specific set of features, if movement were not involved. We now turn to the actual observed counts.
Number of matching configurations and frequencies in Italian (It), French (Fr) and English (En).
| Matches | It | %it | Fr | %fr | En | % |
|---|---|---|---|---|---|---|
| 4 | 520 | 0.27 | 585 | 0.15 | – | – |
| 3 | 851 | 0.45 | 1533 | 0.38 | 693.5 | 0.33 |
| 2 | 424.5 | 0.22 | 1462 | 0.36 | 701.5 | 0.33 |
| 1 | 86.5 | 0.05 | 420 | 0.10 | 479 | 0.23 |
| 0 | 15 | 0.01 | 41 | 0.01 | 243 | 0.11 |
5 Intervention effects in cleft structures in UD treebanks
This section presents, first, the results of the collection of clefts structures and their manual analysis, classifying them into subject, object or adjunct clefts, to answer H1 (subsection 5.1). Then, it compares expected and observed counts in object clefts structures, verifying whether the difference between expected and observed counts predicted in H2 is confirmed (in subsection 5.2). Third, subsection 5.3 deals with expected and observed counts in subject clefts: we should not see any asymmetries as predicted by H3. The section concludes with a discussion of frequency in cleft structures.
5.1 Collecting clefts
For the collection of the observed counts, we exploit all the available UD treebanks to obtain higher frequencies of clefts structures.9
5.1.1 Materials
We make use of four French treebanks: the above mentioned Gsd (Guillaume et al. 2019), Sequoia (Candito & Seddah 2012, Bonfante et al. 2018, 3099 trees, medical, news, nonfiction, wiki), spoken10 (2789 trees, spoken) and the French version of ParTut (Sanguinetti & Bosco 2015, 1020 trees, legal, news and wiki).
We also used four Italian treebanks: beyond Isdt (Bosco et al. 2014), we also used the Venice Italian Treebank Vit (Alfieri & Tamburini 2016; 10087 trees; news, nonfiction), the PoSTWITA (Sanguinetti et al. 2017; 6713 trees; social), and the Twittiro (Cignarella et al. 2018; 1424 trees; social).
Five treebanks were chosen for English: Gum 2.5 (Zeldes 2017), Ewt 2.5 (Silveira et al. 2014; trees 16622; blog, email, reviews, social), Pud 2.511 (1000 trees; news, wiki), LinES 2.5 (Ahrenberg 2015; 5243 trees; fiction, nonfiction, spoken) and ParTut 2.5 (Sanguinetti & Bosco 2015; 2090 trees; legal, news, wiki).
5.1.2 Search
All the materials have been extracted with the Grew-match tool maintained by Inria in Nancy (http://match.grew.fr). The actual query looked for a set of variables detecting cleft structures according to the relevant lexical materials in the languages under investigation. Our queries were language specific, looked for a clefted element x governing a copula dependency on an element y, a complementizer z (e.g., fr. que and qui, it. che, en. that, which, etc.) and a lexical language specific pronoun w (e.g. fr. c’, en. it), such that w directly precedes y, the element y precedes linearly x, and the clefted element x directy precedes the complementizer element z.12 The manual analysis excluded clear cases of non-clefted elements that the query retrieved, such as the English sentence it is a good thing that the details of Members attendance are corrected (English, ID: lines-ud-dev-doc5-3740).
We did not exclude cases of (it-)cleft look-alikes involving restrictive relative clauses from our counts (Cesare et al. 2014; Karssenberg 2017). These structures are composed of a presented “clefted” XP, as given in (6) for Italian, followed by a restrictive relative clause (Karssenberg & Lahousse 2018: 516). These configurations make use of a restricted relative clause, which involves the type of movement and the type of intervention effects investigated in this work. Hallmarks of movement can be detected via reconstruction effects, as given in (6), in which the possessive pronoun is bound to the subject of the restrictive relative clause.
- (6)
- [SpecTP
- È
- Is
- [
- una
- a
- suai
- her
- battaglia
- battle.f.sg
- che
- that
- [IP
- la
- the
- deputatai
- deputy.f.sg
- non
- not
- abbandona]
- abandon.3.sg
- ‘It is a battle of her that the deputy won’t leave’
In practice, we found only one case of a “presented” object followed by a relative in English, It is a very good article which no meat-eater can read (English, EWT-at0033), two for Italian and five for French. In (7), two naturally occurring examples are shown, one from Italian, (7)a, and one from French, (7)b.13
- (7)
- a.
- È
- Is
- un
- an
- incremento
- increase
- che
- that
- neppure
- even.neg
- gli
- the
- assessori
- city-councilors
- sanno
- know
- spiegare
- explain
- ‘It is an increase that even the city councilors are not able to explain’ (Italian, tut-2968)
- b.
- C’est
- It.is
- un
- an
- outrage
- outrage
- que
- that
- nous
- we
- n’
- neg
- acceptons
- accept
- pas
- neg
- ‘It is an outrage that we don’t accept’ (French, Spoken-Rhap_D2006-2)
5.1.3 Results
Our results confirm similar distributions of clefts in corpora in Italian and French as previously observed in spoken corpora (Roggia 2008) and for English, French and Italian in the parallel treebanks of the European Parliament proceedings (Dufter 2009: 90). Table 3 shows that cleft structures represent a very little proportion of the data, less than 1% in the three languages under investigation (0.008% in French, 0.006% in Italian and 0.003% in English). The different distributions may suggest that, in French, cleft formation are more productive than in Italian and in English. A plausible reason is that cleft structures in French are a preferred strategy in answering questions (Belletti 2010).
Number of cleft structures in Italian, French and English and the proportion over the number of trees of the collected treebanks.
| Language | treebanks | trees | clefts | %freq |
|---|---|---|---|---|
| Italian | Isdt, Vit, PoSTWITA, Twittiro | 32391 | 208 | 0.006 |
| French | Gsd, Sequoia, Spoken, ParTut | 23250 | 182 | 0.008 |
| English | Gum, Ewt, Pud, LinES, ParTUT | 30382 | 92 | 0.003 |
Table 4 shows the manually-collected total raw counts of cleft structure and their partition into the subtypes that are of interest to us here: subject (subj), object (obj), adjunct (adj). The distribution in French shows a higher productivity of subject clefts (0.47) over object clefts (0.13). A good proportion of clefts are also adjunct clefts (0.40), whose nature is investigated in section 6. Similar distributions are observed in Italian and in English. In both languages, subject clefts (respectively 0.22 and 0.26) are produced with a higher frequency than object clefts (respectively 0.09 and 0.08), but with a lower percentage than adjunct clefts (respectively 0.69 and 0.66). These results were also predicted in Belletti (2010): French adopts the strategy of clefts for focalizing verbal arguments (subject, object) in a more productive way than Italian (or English).
Typology of cleft structures in Italian, French, and English.
| Language | Total | Subj | %subj | Obj | %Obj | Adj | %adj |
|---|---|---|---|---|---|---|---|
| Italian | 208 | 45 | 0.22 | 19 | 0.09 | 144 | 0.69 |
| French | 182 | 86 | 0.47 | 23 | 0.13 | 73 | 0.40 |
| English | 92 | 24 | 0.26 | 6 | 0.07 | 62 | 0.67 |
Table 4 already confirms our H1 and previous literature, as raw counts of subject clefts are clearly higher than counts for object clefts for the three languages under investigation. More detailed counts of the feature matching configurations are given in the appendices. We now turn to verifying the more specific hypotheses. Recall:
H2: In object clefts, the observed counts of feature-matching configurations are expected to be lower than their expected counts, and the observed count of mismatching configurations should be equal or higher than their expected counts.
H3: In subject clefts, the observed counts of both feature-matching and mismatching configurations are expected to be approximately equal to their expected counts.
Verification of these hypotheses requires comparing the observed counts of cleft constructions to their expected counts, calculated based on the counts of the canonical configurations. The expected counts for each combination of features are calculated by scaling the proportion of that combination of features to the size of the dataset in question. For example, the expected counts of a four-feature match in Italian in a object-oriented cleft is given by the proportion of four-feature matches in canonical sentences in Italian scaled by the number of object-oriented clefts. Numerically, this calculation will correspond to 0.27 (the proportion of four-feature matches in Italian, see Table 3) multiplied by the size of object-oriented clefts, namely 19 (see Table 4), which gives us an expected count of 5.13.
Whether these expected and observed counts confirm or reject the hypothesis is established by a binomial test. The binomial test gives us the probability of k successes in n independent trials, given a base probability p of an event. So, for example, the binomial distribution tells us the probability of a four-feature match in Italian in a subject-oriented cleft. The event in this case is the cleft construction (whose probability is indicated, for example, as 0.006 in Italian). The quantity n is the number of four-matching features in a canonical configuration, and k is the number of four-matching features in a subject-oriented cleft. If certain conditions are met, the binomial distribution can be approximated by the normal distribution and a significance test can be performed. We calculate the cumulative probability distribution: the probability that the observed counts are exactly as observed, or greater, if the observed counts are larger than the expected counts, or the probability that the observed counts are exactly as observed, or smaller, if the observed counts are smaller than the expected counts. The z-score gives us the (one-tailed) probability of exactly, or greater/smaller counts than the expected counts. We first operate on object clefts in subsection 5.2 and then we turn in investigating subject clefts in 5.3 where no intervention effects are active.
5.2 Hypothesis 2: object clefts
We clearly observe cases of intervention effects in object clefts. Comparing between expected and observed counts, asymmetries between feature-matching and feature-mismatching configuration clearly emerge. The calculations of expected counts and actual observed counts, the probabilities of these observations under a binomial distribution and their statistical significance are shown in Table 5 for the three languages.
Expected counts and observed counts for object clefts. Numbers in parentheses are the ceiling or floor rounding to the nearest integer. p is the prior probability of the event. Binomial p indicates the probability of the observed counts under a binomial distribution (the binomial test). z-p is the statistical significance of the binomial probability. n.v. indicates that conditions are not met for a valid calculation of statistical significance. The z-p gives us the (one-tailed) probability of exactly the observed, or greater/smaller counts than the expected counts, for α = 0.5.
| Italian | ||||||
|---|---|---|---|---|---|---|
| Matches | Exp. | Obs. (k) | N | p | Binomial p | z-p |
| 4 | 5.13 | 1 | 520 | 0.006 | 0.18104969 | 0.178810 |
| 3 | 8.55 | 4 | 851 | 0.006 | 0.17191484 | 0.393968 |
| 2 | 4.18 | 5.5 (6) | 424.5 | 0.006 | 0.02960800 | 0.031946 |
| 1 | 0.95 | 7 | 86.5 | 0.006 | 0.00000108 | 0.000001 |
| 0 | 0.19 | 1.5 (2) | 15 | 0.006 | 0.00358865 | 0.000001 |
| Total | 19 | 19 | 1897 | 0.006 | 0.01084956 | 0.017164 |
| French | ||||||
| Matches | Exp. | Obs. (k) | N | p | Binomial p | z-p |
| 4 | 3.45 | 0 | 585 | 0.008 | 0.00910601 | 0.026191 |
| 3 | 8.74 | 3.5 (4) | 1533 | 0.008 | 0.00616952 | 0.013009 |
| 2 | 8.28 | 6.5 (7) | 1462 | 0.008 | 0.10271964 | 0.109001 |
| 1 | 2.30 | 8.5 (9) | 420 | 0.008 | 0.00745894 | 0.002436 |
| 0 | 0.23 | 4.5 (5) | 41 | 0.008 | 0.00001932 | 0.000001 |
| Total | 23 | 23 | 4041 | 0.008 | 0.01838555 | 0.059511 |
| English | ||||||
| Matches | Exp. | Obs. (k) | N | p | Binomial p | z-p |
| 3 | 1,98 | 1 | 693.5 | 0.003 | 0.38384368 | 0.343122 |
| 2 | 1.98 | 2 | 701.5 | 0.003 | 0.27032018 | 0.392847 |
| 1 | 1.38 | 1 | 479 | 0.003 | 0.34177669 | 0.479012 |
| 0 | 0.66 | 2 | 273 | 0.003 | 0.19795469 | 0.225536 |
| Total | 6 | 6 | 2147 | 0.003 | 0.15837421 | 0.490713 |
Results
The expected interaction is numerically clear in all three languages under investigation. As it can be observed, the counts of matching configurations are lower than expected and counts of mismatching configurations are higher than expected. In French and Italian, the situation is extremely clear. If all the features of the dislocated object match with those of the subject, the number of observed counts (k) decreases. For example, as it can be seen in Table 5, prior probabilities suggested that, due to the proportion of cleft clauses found in our French corpora and the distribution of features found in SVO sentences, we should expect around 3.45 object clefts having four matching features; however, 0 are observed (similarly in Italian: 5.13 expected, 1 observed given in (8), a case of a cleft-look alike).
- (8)
- È
- Is
- una
- a
- campionessa
- championf.s
- che
- that
- la
- that
- Gran
- Great
- Bretagna
- Britain
- rimpiangerà
- regretfut
- a
- for
- lungo.
- long
- ‘She is a champion that Great Britain will regret for a long time’ (ID: isst-tanl-2357)
The differential between expected and observed decreases with 3 matching features, while with 2 matching features expected and observed counts are similar, as predicted. Finally, in full mismatching configurations (0 matches) we can observe a high number of observed clefts in all languages with respect to the expected counts (French 0.23 expected, 4.5 observed; Italian 0.19 expected, 1.5 observed; English 0.66 expected, 2 observed). An example of a full mismatching configuration in French is given in (9).
- (9)
- C’est
- It.is
- du
- of
- bon
- good
- boulot
- job
- que
- that
- vous
- you
- m’
- have.1pl
- avez
- to-me
- fait,
- made
- les
- the
- gars!
- boys
- ‘It is a good job that you have done for me, pals’ (ID: gsd-ud-train-13282)
We now turn to subject clefts in section 5.3. In this case, expected counts should be similar to observed counts, since no intervention effects plays a role.
5.3 Hypothesis 3: subject clefts
Analogously to the object clefts, we here investigate only those subject clefts with transitive verbs and therefore sentences with both subjects and objects overtly realized.14 Interestingly, the distribution of transitive and intransitive verbs in French and Italian is similar. In French, out of 86 clefts, 56% (k = 49) are transitive, while in Italian the proportion is equally distributed 22 out of 45 (49%). English shows an uneven distribution with 75% of transitive verbs among the retrieved clefts (k = 18). Differently from object clefts, we should not observe clear asymmetries between expected and observed counts, but rather the number of the observed counts should be approximately equal to their expected counts. Table 6 shows the results.
Expected counts and observed counts for subject clefts. Numbers in parentheses are the ceiling or floor rounding to the nearest integer. p is the prior probability of the event. Binomial p indicates the probability of the observed counts under a binomial distribution (the binomial test). z-p is the statistical significance of the binomial probability. n.v. indicates that conditions are not met for a valid calculation of statistical significance. The z-p gives us the (one-tailed) probability of exactly the observed, or greater/smaller counts than the expected counts, for α = 0.5.
| Italian | ||||||
|---|---|---|---|---|---|---|
| Matches | Exp. | Obs. (k) | N | p | Binomial p | z-p |
| 4 | 5.94 | 7 | 520 | 0.006 | 0.02501811 | 0.027472 |
| 3 | 9.90 | 9 | 851 | 0.006 | 0.03925242 | 0.065965 |
| 2 | 4.84 | 4.5 | 424.5 | 0.006 | 0.07007226 | 0.110322 |
| 1 | 1.10 | 1.5 | 86.5 | 0.006 | 0.08074821 | 0.087276 |
| 0 | 0.22 | 0 | 15 | 0.006 | 0.91368347 | 0.085221 |
| Total | 22 | 22 | 1897 | 0.006 | 0.00170776 | 0.001314 |
| French | ||||||
| Matches | Exp. | Obs. (k) | N | p | Binomial p | z-p |
| 4 | 7.35 | 13 | 585 | 0.008 | 0.99965524 | 0.000142 |
| 3 | 18.62 | 15.5 (16) | 1533 | 0.008 | 0.17446841 | 0.176766 |
| 2 | 17.64 | 15 | 1462 | 0.008 | 0.20039839 | 0.205198 |
| 1 | 4.90 | 5 | 420 | 0.008 | 0.12430300 | 0.266175 |
| 0 | 0.49 | 0.5 (1) | 41 | 0.008 | 0.23787058 | 0.381504 |
| Total | 49 | 49 | 4041 | 0.008 | 0.00135818 | 0.002147 |
| English | ||||||
| Matches | Exp. | Obs. (k) | N | p | Binomial p | z-p |
| 3 | 5.94 | 8 | 693.5 | 0.003 | 0.99969246 | 0.000085 |
| 2 | 5.95 | 8 | 701.5 | 0.003 | 0.99966939 | 0.000097 |
| 1 | 4.14 | 2 | 479 | 0.003 | 0.42109640 | 0.479012 |
| 0 | 1.98 | 0 | 273 | 0.003 | 0.44032994 | 0.362036 |
| Total | 18 | 18 | 2147 | 0.003 | 0.00008826 | 0.000006 |
Results
As expected, mismatching configurations in features do not increase the frequency contrary to object clefts. Results are quite similar in the three languages under discussion. We observe a marginal increase of full matching configurations (4 matches in Italian and French, 3 matches in English). The occurrence of observed configurations with intermediate levels of matching (e.g. 1, 2, 3 matches in Italian and French) are approximately equal to the expected counts. The situation in English is less clear due to the reduced combinations of features, but we can observe that the figures show a similar distribution among the four possible matching configuration (3 and 2 matches expected respectively 5.94 and 5.95, observed 8). We observe that in subject clefts, since there is no intervention at play, the mismatching configurations do not result in an amelioration and consequently these structures do not surface with higher frequency with respect to the expected counts.
5.4 Discussion
As predicted by intervention, a clear asymmetry emerges between subject and object clefts. Moreover, as predicted by a feature-based specification of intervention, when intervention is at play (object clefts), the differences are gradual and suggest that the number of matching features matters. The same (or an opposite) correlation does not arise in subject clefts.
Figure 2 shows the correlations on the aggregated data. In object clefts, we find a negative correlation of the difference between observed counts and expected counts and the number of matching features. We do not find a significant correlation in subject clefts.
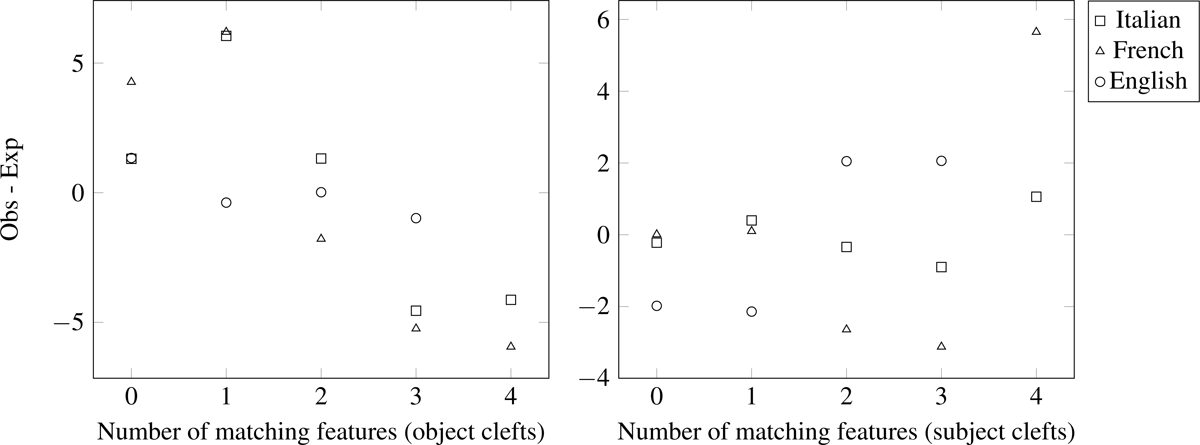
Difference between observed and expected counts as a function of the number of matching features in object clefts (left panel, Pearson r = –0.79, p < .05) and in subject clefts (right panel, Pearson r = 0.41, p = 0.12).
All the hypotheses based on the theoretical account of intervention effects are confirmed. On the basis of the elements presented in subsections 5.2 and 5.3, we have observed that the asymmetry between subject and object clefts is confirmed. The corpus investigation reported here provides a new contribution (in the spirit of Samo & Merlo 2019) to the debate about the role of features in intervention effects. Our results provide a more articulate characterisation of intervention locality.
Despite the limited number of naturally occurring clefts extracted from syntactically annotated corpora in this work, we do observe a numerically clear trend, especially if we compare the distribution of features of the two relevant configurations under investigation.15
Another important contribution of this analysis is the observation of the frequent occurrence, especially in Italian and English, of another type of cleft construction, adjunct clefts, whose locality properties were not dicussed in Belletti (2015). Section 6 investigates the nature and the intervention effects in these structures.
6 A further puzzle: adjunct clefts
One observation concerning the data of Table 4 in section 5 is that a large proportion of the data is represented by adjunct/adverbial clefts. Adverbials are relatively frequent in clefts, depending on the nature of the adverbial (see, for example, on Italian solo ‘only’ and English only cleft in De Cesare & Garassino 2015, manner and cause adverbials or cohesive clefts, as discussed in (Van den Steen 2005; Stark 2014; De Cesare 2019). So it is important to determine their properties and see if they confirm the spirit of our approach. In this section we ask: Do adjunct clefts behave like subjects or like object clefts? Do we find intervention effects?
Not all adverbial clefts are expected to trigger intervention effects. The subject is an intervener in terms of locality only if the adverbial element undergoes movement, as it is extracted from the syntactic structures and it is not directly merged in the higher structure of the cleft (the layer of the copula).16 We can represent this difference as (10) and (11). In (10), we observe modifiers that are not extracted and clefted, but they might be simply generated in the IP of the higher clause (Cinque 1999). Even if it surfaces as a cleft, the configuration might be considered a simple predicative structure of the type (it is clear that…) or (it is obvious that…). No intervention is at play, since the related sentential adverb (e.g., clearly, obviously, etc.) is directly generated in the IP of the higher clause and it does not cross any intervener.
| (10) | IP generated adverbial |
| [SpecTP C’est [AdvP ADV [FP [IP S V O]]]]] |
On the other hand, there are cases in which adverbial/complement elements are generated in the IP of the lower clause and then they move, like the objects, to the relevant left peripheral positions and thus clefted (Schweikert 2005). The derivation is given in (11).
| (11) | Extracted adverbial |
| [SpecTP C’est [AdvP [FP ADV [IP S <ADV> V O]]]]] |
To remove the confound produced by the clauses of type (10), in collecting our counts, we manually analyse the results and only consider the cases of adverbials that unambiguously have undergone movement from the lower clause.17
Adverbials do not bear any person marking and not every adverbial is marked with number or gender features, so that the only possible feature that could result in intervention effects with all adverbials is the feature type: adverbs can be realized as head elements (e.g. never in English) or a maximal projection xp having nominal elements features (e.g. the day before yesterday in English) in the three languages under investigation here. We conjecture, then, that the intervention effect is weaker than a full feature match, because only one feature matches, but stronger than the equivalent one-feature match in object clefts because the matching feature is a larger proportion of the smaller total number of features at play.18 We can thus formulate a fourth hypothesis to be investigated in this section: adjuncts exhibit intervention effects in clefts, but in a weaker form than objects.
H4: In adjunct clefts, the observed counts of feature-matching configurations for the feature Type should be marginally lower than their expected counts, and the observed count of mismatching configurations should be equal or marginally higher than their expected counts.
We estimate the expected counts of adjuncts with a method that differs from the one presented in the previous sections. This is necessary to reach reliable counts since not every canonical structure shows the presence of both subject and overt adverbials, as explained in the next subsection.
6.1 Expected counts on adverbial clefts
The calculation of intervention in adverbial contexts takes into account only the feature type. The materials we sample to count the feature are, for Italian and French, the same treebanks used before, as reported in section 4; for English, we select the biggest treebank available in terms of trees, namely Ewt 2.5 (Silveira et al. 2014; trees 16622; tokens 254856; blog, email, reviews, social).
The method we use for the estimation of expected counts with adverbial elements needs to be adapted. We cannot calculate expected counts simply on the co-occurrence of subjects and adverbials, analogously to what was done for subjects and objects, because adverbs are not selected by the argument structure of the verb. Consequently, the expected counts for adverbial clefts are not estimated on the joint distribution of the values of two random variables representing the different type values of subjects and adverbials (analogously to what was done for subjects and objects above), but calculated by the product of the two random variables and their possible value distributions separately: P(S = si, A = ai) = P(S = si) P(A = ai) for all possible values of i. Mathematically, this means we apply an independence assumption to the distribution of subjects and adverbs, to represent the fact that adverbs are not selected by the verb: linguistically, we expect their distribution to be independent of those of subjects. So, not only is this independence assumption useful in combating sparse data in our counts, but it also corresponds better, we believe, to the linguistic nature of adverbials. For the counts, we take into consideration all subjects and adverbs within a treebank.
The values of the feature type of subjects are (head, xp, null) and of the adverbial elements (head, xp). The counts for xp and head subjects are based on the part-of-speech tag of the subject dependent. The difference between xp and head was retrieved based on parts-of-speech tags (PoS): nouns and proper nouns are xp, and pronominal instances are head. The counts for the null subject are based on inflected verbs without a subject dependency.19 The tool Grewmatch retrieves the first 1000 sentences and indicates what percentage of the corpus those counts are drawn from. Therefore, we create an estimate for null subjects expected counts based on this sample (calculated as counts/%corpus).
For adverbs, we used several sources of information to identify the value of the feature type. In some cases, we counted the value of the feature type in terms of Pos tags of the elements governed by the dependency relation advmod in the annotation scheme of UD (Zeman et al. 2020). We considered adpositions, pronouns and particles as head, and we labelled determiners, adjectives, nouns and proper nouns as xp. We did not count a subset of PoS tags (Ncl in appendix), such as non-annotated elements, conjunctions and verbs. The adverbial PoS tag adv is ambiguous between head or xp, but it represents a good portion of the data. In this case, we developed a query to extract all the occurrences of adverbials.20 Then, a sample of 1000 sentences for every language were selected and analysed manually. Following Cinque (1999), we labelled xp all the adverbial generated in the specifier position of an IP-internal functional projections, such as those adverbs bearing prepositions or morphemes as -mente in Italian, -ment in French, and -ly in English. Table 7 summarizes the results showing the probability of a subject being xp, head, null and an adverb being xp, head, in the different treebanks. The more detailed relevant tables are provided in the Appendix.
Distribution of the feature type for subjects and adverbs.
| Language | Subject | Adverb | |||
|---|---|---|---|---|---|
| xp | head | null | xp | head | |
| Italian | 0.65 | 0.20 | 0.15 | 0.23 | 0.77 |
| French | 0.57 | 0.43 | 0.00 | 0.22 | 0.78 |
| English | 0.35 | 0.63 | 0.02 | 0.24 | 0.76 |
6.2 Results: adverbial clefts
The expected counts discussed above are compared to the observed counts retrieved from the materials discussed in Table 3 in section 5. The results are given in Table 8. As it can be observed, only one fifth of the cleft elements are extracted in Italian and only one element is extracted in English.21 French is more productive and shows a good portion of extracted elements. Since English does not provide enough evidence, in what follows, we perform our analysis of adverbials only on French and Italian.
A manual analysis of adverbial clefts, whether plausibly generated in the higher clause (IP) or moved from the lower clause (Extracted) creating intervention effects.
| Language | Total | IP | Extracted |
|---|---|---|---|
| Italian | 144 | 116 (0.81) | 28 (0.19) |
| French | 57 | 26 (0.46) | 31 (0.54) |
| English | 62 | 61 (0.98) | 1 (0.02) |
Hypothesis H4 states that in adjunct clefts, the observed counts of feature-matching configurations for the feature Type are expected to be lower than their expected counts, and the observed count of mismatching configurations should be equal or higher than their expected counts.
We manually coded the case of matching or mismatching configurations. Table 9 shows the results of observed and expected counts. As it can be observed, there is a marginal decrease in observed matching configurations and a marginal increase in observed mismatching configurations. This is expected, if we recall that only the feature type was taken into account and therefore adverbial elements behave as “intermediate” levels of matching configurations (1 and 2 matches), compared to object clefts in Table 5. Results seems to confirm that the effect of locality is small, but present, with a marginal preference for mismatching configurations.
Expected versus observed counts for adjunct clefts in French and Italian. p is the prior probability of the event. Binomial p indicates the probability of the observed counts under a binomial distribution (the binomial test). z-p is the statistical significance of the binomial probability. The z-p gives us the (one-tailed) probability of exactly the observed, or greater/smaller counts than the expected counts, for α = 0.5.
| Match.configurations | ||||||
|---|---|---|---|---|---|---|
| Language | Exp. | Obs. (k) | N | p | Binomial p | z-p |
| FR | 14.29 | 13 | 12939 | 0.008 | 0.00000001 | 0.000001 |
| IT | 8.50 | 6 | 10464 | 0.006 | 0.00000001 | 0.000001 |
| Mismatch.configuration | ||||||
| Matches | Exp. | Obs. (k) | N | p | Binomial p | z-p |
| FR | 16.71 | 18 | 12939 | 0.008 | 0.000001 | 0.000001 |
| IT | 19.50 | 22 | 10464 | 0.006 | 0.000001 | 0.000001 |
7 Discussion
In this paper, we establish several results, predicted by an intervention locality theory of cleft formation and acceptability. The contributions are three-fold. We provide further evidence in support of the predictions of an intervention theory of locality, based on comparisons of quantitative properties of grammatical data. The fact that we find quantitative confirmation also supports our view of the interaction between observational properties of use and grammar, where the latter leads the former. Finally, we provide a relatively simple and precise methodology that can be used as a blueprint for many other theory-driven quantitative studies.
7.1 Extending the supporting empirical evidence
The quantitative evidence reported here lends support to the predictions of an intervention theory of locality. First, we establish that the quantitative properties of cleft constructions reproduce the binary distinction visible in the qualitative difference of available interpretations between subject and object clefts. This is confirmed by two results. On the one hand, subject clefts, where no intervention is at play, are more frequent than object clefts, where intervention is at play. On the other hand, object clefts are less frequent than expected in intervention configuration, while subject clefts are roughly as frequent as expected. These findings then contribute to the linguistic and psycholinguistic investigation of the formal encoding of long-distance dependencies, following the theoretical lines laid in the first formulation of intervention theory of long-distance dependencies (Rizzi 1990), made gradual and more fine-grained in subsequent work (Rizzi 2004), and verified esperimentally in both sentence processing and acquisition (Franck et al. 2015; Villata et al. 2016; Friedmann et al. 2009).
Second, we also find that the differential and direction of difference between expected and observed counts is directly proportional to the number of features that establish the intervention, the strength of the intervention. This result provides further support to a feature-based definition of intervention and a feature-based notion of strength of intervention, where each feature contributes to the global effect in a cumulative fashion.
Furthermore, this aspect of the result contributes one piece of evidence to finer-grained distinctions among intervention theories. The literature usually distinguishes between narrow and broad intervention approaches. Narrow intervention approaches are grammar-based, are mostly developed to explain ungrammaticality, and consider that the features relevant to define intervention are only those morpho-syntactic features that trigger movement. They don’t expect, for example, that semantic features would be relevant to define intervention (see Brandt et al. 2009; Adani 2012; Martini 2019). On the other hand, cue-based memory models define the notion of intervention more broadly. They are based on processing and are developed to explain more gradual difficulties. Similarity, and consequently intervention, can take any feature type into account (as demonstrated in experiment on semantic reversibility, for example) and intervention is a kind of interference at retrieval in memory (Smith et al. 2021 and reference therein). We provide new quantitative data derived by a feature-based explanation, but that that correlate with a gradient of corpus counts. In this way, we expand the set of evidence on which the two approaches could be tested. In particular, the grammar-based approach will need to be developed in detail to formalise better the notion of strength of intervention and the mechanisms giving rise to gradient grammaticality judgements and corpus counts.
While we have not provided in this paper a direct mechanistic model of intervention, the outcome of our quantitative investigations are relevant for the increasing body of computational research that attempts to reverse engineer current neural networks models to establish the boundaries of what they can learn. These studies have concentrated on structural grammatical competence, exemplified by long-distance agreement and relative clauses and islands, phenomena that also trigger locality effects, and have demonstrated that neural networks can learn long-distance dependencies to an interesting extent (Linzen et al. 2016; Wilcox et al. 2018), but do not fully show intervention effects (Merlo & Ackermann 2018; Merlo 2019). The results of the current paper are relevant for this debate as they demonstrate that any discrepancies between the human results and the machine results are not due to lack of sufficient statistical signal in the data, but are morel likely to be found in properties of the learning algorithms.
7.2 The interaction between usage and grammar
Our work can also be read as a specific proposal on the role of quantitative properties in the theories of grammar. Frequency is a puzzling property of language constructs, whose correlation with other aspects of grammatical representations or other linguistic observations is not clear. Most linguistic approaches are in agreement in assuming that frequencies are an expression of language use, but their views of the relationship to grammar diverge.22 Functionalists assume that usage shapes grammar, and that frequency of use is the cause of some prominent linguistic effects (see Bybee 2007; 2010, among many others). In usage-based theories, frequency of linguistic events determines how automatised, how entrenched, how easy to memorise, how robust they are to change (Tomasello 2009; Evans & Levinson 2009; Bybee 2010; Ibbotson 2013). Linguistic structure is the emergent property shaped by more general cognitive principles of categorisation, generalisation, analogy. The mechanisms by which structure emerges are not always clear, but they are assumed to be based on the combined effect of frequency and similarity, which give rise to grammatical schemas and categories.
For example, Bybee (2007) and others have argued that exemplar theory provides a specification of how frequency effects bring about structure in language. Categories are are induced from observed instances with overlapping properties that are grouped together in memory. Frequency distributions and their direct relation with structural recursion or their inverse relation with some notions of acquisition or processing complexity have also been explained as an effect of pressure for efficient communication (Dryer 1992; 2009; Hawkins 1994; 2004; Gibson 1998; Tily et al. 2011; Zipf 1949).
From a generative or cognitive point of view, frequencies are not part of the grammar or the cognitive system (see an early discussion in Pinker 1991, and a few, notable recent exceptions, such as Yang 2016; Yang et al. 2017). This point of view assumes that frequency-based, quantitative properties of text are unrelated to the underlying grammatical representations of language that linguistic theory proposes.
In this paper, we develop a point of view on frequency that tries to reconcile these views and is based on the idea that frequency is neither the independent variable in the explanation nor irrelevant to language. Current large-scale, syntactically-annotated resources for several languages allow us to develop investigations of the correlation between quantitative linguistic properties and theory-driven abstract linguistic representations and operations. Quantitative confirmation of the theory and its precise internal aspects (kind and size of feature set, for example) also supports our view of the interaction between observational properties of use and underlying abstract grammatical principles. As observed in the introduction, following Merlo (2016) and related works, we use corpus counts in the spirit of the computational quantitative syntax framework: differentials in observed and expected counts are the expression of underlying grammatical properties.
This point of view on the interaction between grammar and corpus frequencies is different from a point of view where corpus frequencies are expressions of usage only and determine the shape of the grammar. We think that the usage-based point of view predicts that observed counts are the same as the expected counts. There is no conceptual difference, in that the grammar, being shaped by use, in principle, cannot give rise to expectations that are different from observations. Lack of a predictive relation is also expected by a point of view where usage is performance and is unrelated to underlying grammatical competence. The point of view that considers competence and performance two separate and not necessarily related aspects, predicts no correlation, or at least only accidental correlations.
We present a view and a method that predict frequencies of cleft sentences based on formal grammatical principles. The predicted counts are the dependent variable in a grammatical model whose independent variable is the complexity of the representations. Specifically, the complexity of the tree representations and feature-based similarity operations. This methodology assumes that underlying grammatical properties surface quantitatively, once independent influences of use are properly factored out. In so doing, it rejects the usual distinction between competence and performance and it reapportions some aspects of usage and frequency to a theory of competence. More generally, this approach is analogous to the proposal discussed in Bresnan et al. (2001) that a given language’s hard constraints can be mirrored in another language as soft constraints.23 Specifically, Bresnan et al. (2001) observed that the disharmonic configurations for person/arguments avoided in the Salish language Lummi are also statistically, in terms of frequencies, avoided in a corpus of spoken English. We demonstrate in this paper that a similar generalization can be drawn within a single language. The type of similarity in features that create ungrammatical structures (hard intervention effects) are also statistically dispreferred in grammatical structures (soft intervention effects). We here restrict our analysis to cleft structures, but similar methodologies could be implemented in other configurations.
7.3 A method for theory-driven use of observational data
A final contribution of this work is that we provide a relatively simple and precise methodology that can be used as a blueprint for many other theory-driven quantitative studies. It is important to extend theory-driven grammatical work beyond qualitative introspection and the experimental method. Experimental and observational data integrate the nuanced verification of fine-grained theories that is possible with quantitative data, going beyond sometimes coarse qualitative characterisations. But observational data also bring the added richness of naturally occurring and large-scale data, data that is, in the end, our primary source of evidence.
8 Conclusions
In this work, we have shown that it is possible to provide a fine-grained analysis of clefts and novel evidence based on corpora and corpus counts. The main novel finding is that intervention effects that create ungrammatical structures seems to be present also in grammatical configurations, if one looks at fine-grained quantitative evidence. Further research is required to detect the nature of those elements and their position with respect to principles of locality and extend the findings to more languages.
Abbreviations
1 = first person, 2 = second person, 3 = third person, f = feminine, fut = future, m = masculine, pl = plural, sg = singular.
Notes
- In many natural languages, the displacement co-occurs with a specialized overt particle/marker, for example in Gungbe (Aboh 2004), Abidji (Hager-M’Boua 2014), Japanese (Saito 2012). Theoretical accounts of the same nature have also been provided for in-situ components, such as interrogative elements in Chinese (Huang 1982; Cheng & Rooryck 2000), where the marked syntactic components do not seem to “superficially” move (Bonan 2017). [^]
- Monoclausal accounts have also been provided (Meinunger 1998; Frascarelli & Ramaglia 2013). See Haegeman et al. (2015) for an overview and a comparison between the biclausal and monoclausal models. [^]
- The interaction of locality and functional projections has been central in the study of the comparative dimension of cartographic maps in both theoretical (Haegeman 2012; Abels 2012; Rizzi 2013) and developmental perspective (Friedmann et al. 2020; Moscati & Rizzi 2021). We here adopt standard considerations on intervention effects in the spirit of experimental syntax (Friedmann et al. 2009; Belletti et al. 2012; Martini et al. 2020), without assuming any further properties on the status of the landing site. [^]
- These matching conditions are based on observed acceptability judgements and processing reading times and clearly show that the notion of match in intervention defined here cannot be modelled by the formal notion of unification. [^]
- As noted by an anonymous reviewer, subject-clefts also reflect the standard word order of the languages (SVO), in contrast, for example, with object and adjunct clefts (cf. Aravind et al. 2018). A different formal model should be implemented to uncover asymmetries between simple reorderings versus non-reordering, which is beyond the scope of the paper. [^]
- The values are based on a typological search on the specific values of the parameter of Word Order, extracted from the database of the World Atlas of Language Structures (WALS, Dryer & Haspelmath 2013. https://wals.info/feature/81A#2/18.0/153.1 (accessed, 13.05.2021). [^]
- An example is extracted from the Italian treebank ISDT (ID: isst-tanl-3247): Come prima cosa, 2 volte al giorno, prendi un appuntamento con te stessa. ‘First of all, twice a day, reserve a meeting with yourself’. The mentioned sentence, whose inflected verb is homophonous with the indicative present, represents a case of an imperative that we cannot automatically discriminate. [^]
- Another method to impute the values of the underspecified gender and number features would have been to assume the same distribution as observed feature values in other contexts, such as third person or full noun phrases. This method would assume that these distributions are similar (or even identical) to the one we need to impute. This is a strong assumption that we wish to avoid. We adopt, instead, a uniform distribution, as the most conservative option. A uniform distribution makes the least assumptions about the distribution itself, and implements a maximum entropy model of unknown values. In calculating feature matches, a uniform distribution yields the most entropic matching distribution of two features, and hence constitutes the hardest case to beat for all our hypotheses (see section 3). Our H2 makes prediction of both higher than expected and lower than expected counts, our H3 predicts equal counts and a possible H0 predicts no match between observed counts and expected counts. In all these cases, the maximum entropy distribution will be the hardest case to refute, on average. [^]
- The size of corpus for expected and observed counts is different, but we need to enlarge the number of corpora in order to retrieve as rare a structure as clefts. On the other hand, SVO is a frequent structure and we decided to use the most complete and heterogeneous treebank in each language, as discussed in section 4. [^]
- https://universaldependencies.org/treebanks/fr_spoken/index.html accessed June 14, 2020. [^]
- https://github.com/UniversalDependencies/UD_English-PUD/blob/master/README.md. Accessed June 14, 2020. [^]
- The list of queries can be found in Appendix E. [^]
- We here report the other four cases of cleft-lookalike in French: Mais c’est une hypothèse que je ne veux pas prendre en considération. ‘but it is a hypothesis that I don’t want to take into consideration’ (GSD-fr-ud-train_09322); et euh c’est un endroit que j’aime pas ‘it is a place that i don’t like’ (Spoken-Rhap_D0006-40); donc ça c’est un endroit que j’aime pas trop euh ‘it is a place that i don’t like too much’ (Spoken- Rhap_D0006-43); C’est un site que nous n’oublierons jamais ‘it is a site that we will never forget’ (GSD fr-ud-train_05615). The other Italian occurrence will be discussed in sub-section 5.2, example (8). [^]
- We considered copular sentences as transitive, following Moro 1997, so that we can analyse the case of matching and mismatching configurations between subjects and objects. Reflexive verbs were considered transitives. [^]
- We acknowledge the limitation of our dataset. The dataset, however, was built with a semiautomatic procedure and manually curated, so that even a small amount of data will have enough signal to detect the pattern we are hypothesizing. The development of a finer-grained method able to automatically retrieve clefts (and other complex structures) from unannotated corpora in a larger set of languages will be left to future studies. [^]
- Some kinds of adjunct elements appear to exhibit forms of intervention. Temporal and locative elements are able to satisfy certain types of subject requirements, in the so-called locative inversion in English (Rizzi & Shlonsky 2007) and locative/temporal inversion in other Germanic languages (Samo 2019). It appears, then, that adverbial elements are able to undergo both A and A’-movement (Rizzi 2004), but an adverbial crossing an intervening subject does not trigger the same effects of similarity that is triggered with a crossing object. This difference can perhaps be ascribed to the fact that, feature-wise, adverbials and subjects share only a very partial subset of features, unlike subjects and objects. [^]
- For example, the French modifier vrai ‘true’ is not extracted from the sentence as an IP internal head: the example from the treebank spoken, id:Rhap_D0004-23, “mh mh donc c’est vrai que ça fait quand même euh beaucoup de changements” (lit. ‘interjection then it’s true that it is the same interjection many changes’). [^]
- The precise specification of this similarity calculation requires more empirical support and is left for future work. [^]
- Given that we take into consideration all the subjects in the treebank, we need to account for null subject environments. In Italian, the subject can be omitted in most contexts without triggering ungrammaticality (Rizzi 1982). A form of null subjects in a much reduced set of specific environments (e.g. diary texts) is also allowed in French and English (Haegeman 1990). [^]
- We excluded (negative) polarity items which might have added some noise to the results and whose status in the syntactic architecture is under debate (Moscati 2012). [^]
- The sentence (Treebank GUM, ID:GUM_interview_mckenzie-7, it was a tournament that I wish we ‘d actually gone back to more often). [^]
- According to (Haspelmath 2006: 16), “Frequency of use is a property of parole or performance, not of language structure or competence, and throughout the 20th century most linguists have shown little interest in explaining structure in terms of use.” [^]
- …“the same categorical phenomena which are attributed to hard grammatical constraints in some languages continue to show up as statistical preferences in other languages, motivating a grammatical model that can account for soft constraints”(Bresnan et al. 2001: 1). [^]
Acknowledgements
We thank Caterina Bonan and Francesco-Alessio Ursini for useful comments. All errors are our own.
Funding Information
We gratefully acknowledge the fundamental research fund #20YBB06 for the Central Universities (Science Foundation of Beijing Language and Culture University) to GS and the partial support of the NCCR Evolving Language, Swiss National Science Foundation Agreement #51NF40_180888 to PM.
Competing Interests
The authors have no competing interests to declare.
References
Abels, Klaus. 2012. The Italian Left Periphery: A view from locality. Linguistic Inquiry 43(1). 229–254. DOI: http://doi.org/10.1162/LING_a_00084
Aboh, Enoch Oladé. 2004. The morphosyntax of complement-head sequences: Clause structure and word order patterns in Kwa. Oxford, New York: Oxford University Press. DOI: http://doi.org/10.1093/acprof:oso/9780195159905.001.0001
Adani, Flavia. 2012. Some notes on the acquisition of relative clauses: new data and open questions. In Bianchi, Valentina & Chesi, Cristiano (eds.), Enjoy linguistics! Papers offered to Luigi Rizzi on the occasion of his 60th birthday, 6–13. CISCL Press.
Ahrenberg, Lars. 2015. Converting an English-Swedish Parallel Treebank to Universal Dependencies. In Third International Conference on Dependency Linguistics (DepLing 2015, Uppsala, Sweden, August 24–26, 2015), 10–19. Association for Computational Linguistics.
Alexiadou, Artemis & Law, Paul & Meinunger, André & Wilder, Chris. (eds.) 2000. The syntax of relative clauses (Linguistics Today). J. Benjamins Publishing Company. DOI: http://doi.org/10.1075/la.32
Alfieri, Linda & Tamburini, Fabio. 2016. (Almost) Automatic Conversion of the Venice Italian Treebank into the Merged Italian Dependency Treebank Format. In Proceedings of CLiCit/EVALITA. DOI: http://doi.org/10.4000/books.aaccademia.1683
Andrews, Avery D. 2007. Relative clauses. In Shopen, Timothy (ed.), Language typology and syntactic description, vol. 2. 206–236. Cambridge University Press Cambridge. DOI: http://doi.org/10.1017/CBO9780511619434.004
Aravind, Athulya & Hackl, Martin & Wexler, Ken. 2018. Syntactic and pragmatic factors in children’s comprehension of cleft constructions. Language Acquisition 25(3). 284–314. DOI: http://doi.org/10.1080/10489223.2017.1316725
Ariel, Mira. 1990. Accessing noun-phrase antecedents. London: Routledge.
Beck, Sigrid. 2006. Intervention effects follow from focus interpretation. Natural Language Semantics 14(1). 1–56. DOI: http://doi.org/10.1007/s11050-005-4532-y
Belletti, Adriana. 2010. Structures and strategies. New York: Routledge. DOI: http://doi.org/10.4324/9780203887134
Belletti, Adriana. 2015. The focus map of clefts: Extraposition and Predication. In Shlonsky, Ur (ed.), Beyond functional sequence, vol. 10 (The cartography of syntactic structures), 42–60. Oxford, New York: Oxford University Press. DOI: http://doi.org/10.1093/acprof:oso/9780190210588.001.0001
Belletti, Adriana. 2018. Locality in syntax. In Oxford research encyclopedia of linguistics. Oxford, New York. DOI: http://doi.org/10.1093/acrefore/9780199384655.013.318
Belletti, Adriana & Friedmann, Naama & Brunato, Dominique & Rizzi, Luigi. 2012. Does gender make a difference? Comparing the effect of gender on children’s comprehension of relative clauses in Hebrew and Italian. Lingua 122(10). 1053–1069. DOI: http://doi.org/10.1016/j.lingua.2012.02.007
Belletti, Adriana & Rizzi, Luigi. 2017. On the syntax and pragmatics of some clause-peripheral positions. In Blochowiak, Joanna, Grisot, Cristina, Durrleman, Stephanie & Laenzlinger, Christopher (eds.), Formal models in the study of language, 33–48. Cham: Springer. DOI: http://doi.org/10.1007/978-3-319-48832-5_3
Bentea, Anamaria Jeker. 2015. Intervention effects in language acquisition: The comprehension of A-bar dependencies in French and Romanian. Geneva: University of Geneva, PhD dissertation. DOI: http://doi.org/10.13097/archive-ouverte/unige:87829
Bever, Thomas G. 1974. The ascent of the specious, or there’s a lot we don’t know about mirrors. In Cohen, David (ed.), Explaining linguistic phenomena, 173–200. Washington: Halsted Press.
Bianchi, Valentina & Bocci, Giuliano & Cruschina, Silvio. 2015. Focus fronting and its implicatures. In O. Aboh, Enoch & Schaeffer, Jeannette & Sleeman, Petra (eds.), Romance languages and linguistic theory 2013: Selected papers from ‘going romance’amsterdam 2013, 1–20. John Benjamins Amsterdam. DOI: http://doi.org/10.1075/rllt.8.01bia
Bianchi, Valentina & Frascarelli, Mara. 2010. Is topic a root phenomenon. Iberia 2. 43–48.
Bonan, Caterina. 2017. “c’est” or” sé”? on the cartography of clefts. Generative Grammar in Geneva 10. 131–151. DOI: http://doi.org/10.13097/cjg3-tfud
Bonfante, Guillaume & Guillaume, Bruno & Perrier, Guy. 2018. Application of Graph Rewriting to Natural Language Processing, vol. 1 (Logic, Linguistics and Computer Science Set). ISTE Wiley. https://hal.inria.fr/hal-01814386. DOI: http://doi.org/10.1002/9781119428589
Bosco, Cristina & Dell’Orletta, Felice & Montemagni, Simonetta & Sanguinetti, Manuela & Simi, Maria. 2014. The EVALITA 2014 dependency parsing task. In EVALITA 2014 evaluation of NLP and speech tools for Italian, 1–8. Pisa University Press.
Brandt, Silke & Kidd, Evan & Lieven, Elena & Tomasello, Michael. 2009. The discourse bases of relativization: An investigation of young German and English-speaking children’s comprehension of relative clauses. Cognitive Linguistics 20(3). 539–570. DOI: http://doi.org/10.1515/COGL.2009.024
Bresnan, Joan, Dingare, Shipra & Manning, Christopher D. 2001. Soft constraints mirror hard constraints: Voice and person in English and Lummi. In Proceedings of theLFG01 conference 13. 32. Stanford: CSLI Publications.
Bybee, Joan. 2007. Frequency of use and the organization of language. Oxford University Press. DOI: http://doi.org/10.1093/acprof:oso/9780195301571.001.0001
Bybee, Joan. 2010. Language, usage and cognition. Cambridge University Press. DOI: http://doi.org/10.1017/CBO9780511750526
Candito, Marie & Seddah, Djamé. 2012. Le corpus Sequoia: annotation syntaxique et exploitation pour l’adaptation d’analyseur par pont lexical. In TALN 2012–19e conférence sur le Traitement Automatique des Langues Naturelles. Grenoble, France. https://hal.inria.fr/hal-00698938.
Cecchetto, Carlo. 2000. Syntactic or semantic reconstruction? evidence from pseudoclefts and clitic left dislocation. In Cecchetto, Carlo & Chierchia, Gennaro & Guasti, Maria T. (eds.), Semantic interfaces, 90–144. Stanford CA: CSLI Publications.
Cesare, Anna-Maria De & Garassino, Davide & Marco, Rocio Agar & Baranzini, Laura. 2014. Form and frequency of Italian cleft constructions in a corpus of electronic news: A contrastive perspective with French, Spanish, German and English. In De Cesare, Anna M. (ed.), Frequency, forms and functions of cleft constructions in Romance and Germanic: Contrastive, corpusbased studies, trends in linguistics, 49–100. Mouton de Gruyter Berlin, Munich & Boston. DOI: http://doi.org/10.1515/9783110361872.325
Cheng, Lisa & Rooryck, Johan. 2000. Licensing wh-in-situ. Syntax 3(1). 1–19. DOI: http://doi.org/10.1111/1467-9612.00022
Chesi, Cristiano & Canal, Paolo. 2019. Person features and lexical restrictions in Italian clefts. Frontiers in Psychology 10. 2105. DOI: http://doi.org/10.3389/fpsyg.2019.02105
Chomsky, Noam. 1977. On wh-movement, 71–132. New York: Academic Press.
Cignarella, Alessandra Teresa & Bosco, Cristina & Patti, Viviana & Lai, Mirko. 2018. Application and Analysis of a Multi-layered Scheme for Irony on the Italian Twitter Corpus TWITTIRO. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018).
Cinque, Guglielmo. 1990. Types of Ā-dependencies. Cambridge, MA: MIT press.
Cinque, Guglielmo. 1999. Adverbs and functional heads: A cross-linguistic perspective. Oxford, New York: Oxford University Press.
De Cesare, Anna-Maria. 2019. It is with pleasure that…/it is with pleasure that on manner adverbial clefts expressing emotional states in Italian and French political speeches. Neuphilologische Mitteilungen 120(2). 429–448.
De Cesare, Anna-Maria & Garassino, Davide. 2015. On the status of exhaustiveness in cleft sentences: An empirical and cross-linguistic study of English also-/only-clefts and Italian anche-/solo-clefts. Folia Linguistica 49(1). 1–56. DOI: http://doi.org/10.1515/flin-2015-0001
De Cesare, Anna-Maria & Garassino, Davide. 2018. Adverbial cleft sentences in Italian, French and English. In García, Marco García & Uth, Melanie (eds.), Focus realization in Romance and beyond, 201–255. Amsterdam & New York: John Benjamins Publishing Company. DOI: http://doi.org/10.1075/slcs.201.09dec
Dick, Frederic & Wulfeck, Beverly & Krupa-Kwiatkowski, Magda & Bates, Elizabeth. 2004. The development of complex sentence interpretation in typically developing children compared with children with specific language impairments or early unilateral focal lesions. Developmental Science 7(3). 360–377. DOI: http://doi.org/10.1111/j.1467-7687.2004.00353.x
Doetjes, Jenny & Rebuschi, Georges & Rialland, Annie. 2004. Cleft sentences. In Corblin, Francis & de Swart, Henriette (eds.), Handbook of French semantics, 529–552. Stanford, CA: CSLI Publications.
Dryer, Matthew S. 1992. The Greenbergian word order correlations. Language, 81–138. DOI: http://doi.org/10.2307/416370
Dryer, Matthew S. 2009. Problems testing typological correlations with the onlineWALS. Linguistic Typology 13(1). 121–135. DOI: http://doi.org/10.1515/LITY.2009.007
Dryer, Matthew S. & Haspelmath, Martin. 2013. WALS Online. Leipzig: Max Planck Institute for Evolutionary Anthropology. https://wals.info/.
Dufter, Andreas. 2009. Clefting and discourse organization: Comparing Germanic and Romance. In Dufter, Andreas & Jacob, Daniel (eds.), Focus and background in Romance languages, 83–122. Amsterdam & Philadelphia: John Benjamins Publishing. DOI: http://doi.org/10.1075/slcs.112.05duf
Endo, Yoshio. 2007. Locality and information structure: A cartographic approach to Japanese (Linguistics Today). John Benjamins Publishing. DOI: http://doi.org/10.1075/la.116
Evans, Nicholas & Levinson, Stephen C. 2009. The myth of language universals: Language diversity and its importance for cognitive science. Behavioral and brain sciences 32(5). 429–448. DOI: http://doi.org/10.1017/S0140525X0999094X
Franck, Julie & Colonna, Saveria & Rizzi, Luigi. 2015. Task-dependency and structure-dependency in number interference effects in sentence comprehension. Frontiers in psychology 6. 349. DOI: http://doi.org/10.3389/fpsyg.2015.00807
Frascarelli, Mara. 2007. Subjects, topics and the interpretation of referential pro. Natural Language & Linguistic Theory 25(4). 691–734. DOI: http://doi.org/10.1007/s11049-007-9025-x
Frascarelli, Mara & Hinterhölzl, Roland. 2007. Types of topics in German and Italian. On information structure, meaning and form, 87–116. DOI: http://doi.org/10.1075/la.100.07fra
Frascarelli, Mara & Ramaglia, Francesca. 2013. (Pseudo) clefts at the syntax-prosody-discourse interface. In Hartmann, Katharina & Veenstra, Tonjes (eds.), Cleft structures, 97–138. John Benjamins. DOI: http://doi.org/10.1075/la.208.04fra
Friedmann, Naama & Belletti, Adriana & Rizzi, Luigi. 2009. Relativized relatives: Types of intervention in the acquisition of A-bar dependencies. Lingua 119(1). 67–88. DOI: http://doi.org/10.1016/j.lingua.2008.09.002
Friedmann, Naama & Belletti, Adriana & Rizzi, Luigi. 2020. Growing trees. the acquisition of the left-periphery. Available online at: https://ling.auf.net/lingbuzz/005369. DOI: http://doi.org/10.16995/glossa.5877
Gibson, Edward. 1998. Linguistic complexity: Locality of syntactic dependencies. Cognition 68(1). 1–76. DOI: http://doi.org/10.1016/S0010-0277(98)00034-1
Gibson, Edward & Warren, Tessa. 2004. Reading-time evidence for intermediate linguistic structure in long-distance dependencies. Syntax 7(1). 55–78. DOI: http://doi.org/10.1111/j.1368-0005.2004.00065.x
Gordon, Peter C. & Hendrick, Randall & Johnson, Marcus. 2001. Memory interference during language processing. Journal of experimental psychology: learning, memory, and cognition 27(6). 1411. DOI: http://doi.org/10.1037/0278-7393.27.6.1411
Gordon, Peter C. & Hendrick, Randall & Johnson, Marcus. 2004. Effects of noun phrase type on sentence complexity. Journal of memory and Language 51(1). 97–114. DOI: http://doi.org/10.1016/j.jml.2004.02.003
Gordon, Peter C. & Hendrick, Randall & Johnson, Marcus & Lee, Yoonhyoung. 2006. Similarity-based interference during language comprehension: Evidence from eye tracking during reading. Journal of experimental psychology: Learning, Memory, and Cognition 32(6). 1304. DOI: http://doi.org/10.1037/0278-7393.32.6.1304
Gordon, Peter C. & Hendrick, Randall & Levine, William H. 2002. Memory-load interference in syntactic processing. Psychological science 13(5). 425–430. DOI: http://doi.org/10.1111/1467-9280.00475
Grillo, Nino. 2008. Generalized minimality. Utrecht: University of Utrecht, PhD dissertation.
Grimshaw, Jane & Samek-Lodovici, Vieri. 1998. Optimal subjects and subject universals. In Barbosa, Pilar & Fox, Danny & Hagstrom, Paul & McGinnis, Martha (eds.), Is the best good enough? optimality and competition in syntax, 193–219. Cambridge, MA: MIT Press.
Guillaume, Bruno & de Marneffe, Marie-Catherine & Perrier, Guy. 2019. Conversion et améliorations de corpus du français annotés en Universal Dependencies. Traitement Automatique des Langues 60(2). 71–95. https://hal.inria.fr/hal-02267418.
Gulordava, Kristina & Merlo, Paola. 2020. Computational quantitative syntax: The case of Universal 18. In Romance Languages and Linguistic Theory 16: Selected papers from the 47th Linguistic Symposium on Romance Languages (LSRL), Newark, Delaware 16. 109. John Benjamins Publishing Company. DOI: http://doi.org/10.1075/rllt.16.08gul
Haegeman, Liliane. 1990. Non-overt subjects in diary contexts. In Mascaró, Joan & Nespor, Marina (eds.), Grammar in Progress, GLOW essays for Henk van Riemsdijk, 167–174. Berlin: De Gruyter. DOI: http://doi.org/10.1515/9783110867848.167
Haegeman, Liliane. 2012. Adverbial clauses, main clause phenomena, and composition of the left periphery: The cartography of syntactic structures 8. Oxford University Press. DOI: http://doi.org/10.1093/acprof:oso/9780199858774.001.0001
Haegeman, Liliane & Meinunger, André & Vercauteren, Aleksandra. 2015. The syntax of it-clefts and the left periphery of the clause. In Shlonsky, Ur (ed.), Beyond functional sequence, 73–90. DOI: http://doi.org/10.1093/acprof:oso/9780190210588.003.0005
Hager-M’Boua, Clarissa. 2014. Structure de la phrase en abidji. Geneva: University of Geneva, PhD dissertation. DOI: http://doi.org/10.13097/archive-ouverte/unige:40579
Haspelmath, Martin. 2006. Against markedness (and what to replace it with). Journal of linguistics 42(1). 25–70. DOI: http://doi.org/10.1017/S0022226705003683
Hawkins, John A. 1994. A performance theory of order and constituency. Cambridge: Cambridge University Press. DOI: http://doi.org/10.1017/CBO9780511554285
Hawkins, John A. 2004. Efficiency and complexity in grammars. Oxford: Oxford University Press. DOI: http://doi.org/10.1093/acprof:oso/9780199252695.001.0001
Huang, C.-T. James. 1982. Move wh in a language without wh-movement. The linguistic review 1(4). 369–416. DOI: http://doi.org/10.1515/tlir.1982.1.4.369
Ibbotson, Paul. 2013. The Scope of Usage-Based Theory. Frontiers in Psychology 4. 255. https://www.frontiersin.org/article/10.3389/fpsyg.2013.00255. DOI: http://doi.org/10.3389/fpsyg.2013.00255
Jespersen, Otto. 1937. Analytic syntax. Chicago: The University of Chicago Press.
Karssenberg, Lena. 2017. Ya les oiseaux qui chantent. a corpus analysis of French il y a clefts. Leuven: KU Leuven, PhD dissertation.
Karssenberg, Lena. 2018. Non-prototypical clefts in French: A corpus analysis of french il y a cleft. Berlin: De Gruyter Mouton. DOI: http://doi.org/10.1515/9783110586435
Karssenberg, Lena & Lahousse, Karen. 2018. The information structure of French il ya clefts and c’est clefts: A corpus-based analysis. Linguistics 56(3). 513–548. DOI: http://doi.org/10.1515/ling-2018-0004
Kiss, Katalin É. 1992. Logical structure in syntactic structure: The case of Hungarian. In James Huang, C. T. & May, Robert (eds.), Logical structure and linguistic structure: crosslinguistic perspectives, 111–147. Dordrecht: Springer. DOI: http://doi.org/10.1007/978-94-011-3472-9_5
Kiss, Katalin É. 1998. Identificational focus versus information focus. Language 74(2). 245–273. DOI: http://doi.org/10.1353/lan.1998.0211
Lambrecht, Knud. 2001. A framework for the analysis of cleft constructions. Linguistics 39(3). 463–516. DOI: http://doi.org/10.1515/ling.2001.021
Lewis, Richard L. & Vasishth, Shravan. 2005. An activation-based model of sentence processing as skilled memory retrieval. Cognitive science 29(3). 375–419. DOI: http://doi.org/10.1207/s15516709cog0000_25
Linzen, Tal & Dupoux, Emmanuel & Goldberg, Yoav. 2016. Assessing the ability of lstms to learn syntax-sensitive dependencies. Transactions of the Association for Computational Linguistics 4. 521–535. DOI: http://doi.org/10.1162/tacl_a_00115
Lobo, Maria & Santos, Ana Lúcia & Soares-Jesel, Carla & Vaz, Stéphanie. 2019. Effects of syntactic structure on the comprehension of clefts. Glossa 4. 1–23. DOI: http://doi.org/10.5334/gjgl.645
Martini, Karen. 2019. Animacy does not help french-speaking children in the repetition of object relatives. In Guijarro-Fuentes, Pedro & Suárez-Gómez, Cristina (ed.), Language acquisition and development. proceedings of gala 2017, 221–240. Cambridge Scholars Publishing.
Martini, Karen & Belletti, Adriana & Centorrino, Santi & Garraffa, Maria. 2020. Syntactic complexity in the presence of an intervener: the case of an Italian speaker with anomia. Aphasiology 34(8). 1016–1042. DOI: http://doi.org/10.1080/02687038.2019.1686744
Meinunger, André. 1998. The structure of cleft and pseudo-cleft sentences. In Texas linguistic forum 38. 235–246.
Merlo, Paola. 2016. Quantitative Computational Syntax: some initial results. Italian Journal of Computational Linguistics 2(1). 11–30. DOI: http://doi.org/10.17454/IJCoL02.02
Merlo, Paola. 2019. Probing word and sentence embeddings for long-distance dependencies effects in French and English. In Proceedings of the 2019 acl workshop blackboxnlp: Analyzing and interpreting neural networks for nlp, 158–172. Florence, Italy: Association for Computational Linguistics. https://aclanthology.org/W19-4817. DOI: http://doi.org/10.18653/v1/W19-4817
Merlo, Paola & Ackermann, Francesco. 2018. Vectorial semantic spaces do not encode human judgments of intervention similarity. In Proceedings of the 22nd conference on computational natural language learning, 392–401. DOI: http://doi.org/10.18653/v1/K18-1038
Moro, Andrea. 1997. The raising of predicates: Predicative noun phrases and the theory of clause structure. Oxford: Cambridge University Press. DOI: http://doi.org/10.1017/CBO9780511519956
Moscati, Vincenzo. 2012. The cartography of negative markers: why negation breaks the assumption of LF/PF isomorphism. In Bianchi, Valentina & Chesi, Cristiano (eds.), Enjoy linguistics! Papers offered to Luigi Rizzi on the occasion of his 60th birthday, 6–13. CISCL Press.
Moscati, Vincenzo & Rizzi, Luigi. 2021. The layered syntactic structure of the complementizer system: functional heads and multiple movements in the early left-periphery. a corpus study on italian. Frontiers in Psychology 12. 898. DOI: http://doi.org/10.3389/fpsyg.2021.627841
Ott, Dennis. 2014. An ellipsis approach to contrastive left-dislocation. Linguistic Inquiry 45(2). 269–303. DOI: http://doi.org/10.1162/LING_a_00155
Pinker, Steven. 1991. Rules of language. Science 253(5019). 530–535. DOI: http://doi.org/10.1126/science.1857983
Prince, Ellen F. 1978. A comparison of wh-clefts and it-clefts in discourse. Language, 883–906. DOI: http://doi.org/10.2307/413238
Reeve, Matthew. 2012. Clefts and their relatives. Amsterdam & New York: John Benjamins Publishing. DOI: http://doi.org/10.1075/la.185
Rizzi, Luigi. 1982. Issues in Italian Syntax. Dordrecht: Foris. DOI: http://doi.org/10.1515/9783110883718
Rizzi, Luigi. 1990. Relativized minimality. Cambridge MA: The MIT Press.
Rizzi, Luigi. 1997. The fine structure of the Left Periphery. In Haegeman, Liliane (ed.), Elements of grammar, 281–337. Dordrecht: Kluwer Academic publisher. DOI: http://doi.org/10.1007/978-94-011-5420-8_7
Rizzi, Luigi. 2004. Locality and left periphery. In Belletti, Adriana (ed.), Structures and beyond, vol. 3 (The cartography of syntactic structures), 223–251. Oxford, New York: Oxford University Press Oxford.
Rizzi, Luigi. 2013. Notes on cartography and further explanation. Probus 25(1). 197–226. DOI: http://doi.org/10.1515/probus-2013-0010
Rizzi, Luigi. 2015. Notes on labeling and subject positions. In Domenico, Elisa di & Hamann, Cornelia & Matteini, Simona (eds.), Structures, strategies and beyond: Studies in honour of Adriana Belletti 223. 17. Amsterdam: John Benjamins Publishing Company. DOI: http://doi.org/10.1075/la.223.02riz
Rizzi, Luigi & Shlonsky, Ur. 2007. Strategies of subject extraction. In Sauerland, Uli & Gartner, Hans M. (eds.), Interfaces + recursion = language? Chomsky’s minimalism and the view from syntax-semantics, 115–160. New York: Mouton de Gruyter.
Roggia, Carlo Enrico. 2008. Frasi scisse in italiano e francese orale: evidenze dal C-ORAL-ROM. Cuadernos de filología italiana 15. 9–29.
Ross, John Robert. 1967. Constraints on variables in syntax. Cambridge MA: Massachusetts Institute of Technology, PhD dissertation.
Saito, Mamoru. 2012. Sentence types and the Japanese right periphery. In Zimmerman, Thomas E. & Grewendorf, Gunther (eds.), Discourse and grammar, 147–176. Walter de Gruyter Berlin. DOI: http://doi.org/10.1515/9781614511601.147
Samo, Giuseppe. 2019. A Criterial Approach to the Cartography of V2 (Linguistik Aktuell/Linguistics Today). Amsterdam, Philadelphia: John Benjamins Publishing Company. DOI: http://doi.org/10.1075/la.257
Samo, Giuseppe & Merlo, Paola. 2019. Intervention effects in object relatives in English and Italian: a study in quantitative computational syntax. In Proceedings of the first workshop on quantitative syntax (quasy, syntaxfest 2019), 46–56. Paris, France: Association for Computational Linguistics. https://www.aclweb.org/anthology/W19-7906. DOI: http://doi.org/10.18653/v1/W19-7906
Sanguinetti, Manuela & Bosco, Cristina. 2015. Parttut: The turin university parallel treebank. In Harmonization and development of resources and tools for Italian natural language processing within the parli project, 51–69. Springer. DOI: http://doi.org/10.1007/978-3-319-14206-7_3
Sanguinetti, Manuela & Bosco, Cristina & Mazzei, Alessandro & Lavelli, Alberto & Tamburini, Fabio. 2017. Annotating Italian social media texts in Universal Dependencies. In Fourth International Conference on Dependency Linguistics (Depling 2017), 229–239. Linkoping University Electronic Press.
Schweikert, Walter. 2005. The order of prepositional phrases in the structure of the clause (Linguistik Aktuell/Linguistics Today). Amsterdam: John Benjamins Publishing. DOI: http://doi.org/10.1075/la.83
Shlonsky, Ur. (ed.) 2015. Beyond functional sequence (The Cartography of Syntactic Structures). Oxford, New York: Oxford University Press. DOI: http://doi.org/10.1093/acprof:oso/9780190210588.001.0001
Silveira, Natalia & Dozat, Timothy & de Marneffe, Marie-Catherine & Bowman, Samuel & Connor, Miriam & Bauer, John & Manning, Christopher D. 2014. A Gold Standard Dependency Corpus for English. In Proceedings of the Ninth International Conference on Language Resources and Evaluation (LREC-2014).
Skopeteas, Stavros & Fanselow, Gisbert. 2009. Effects of givenness and constraints on free word order. In Zimmermann, Malte & Fery, Caroline (eds.), Information structure: Theoretical, typological, and experimental perspectives, 307–331. Oxford, New York: Oxford University Press Oxford. DOI: http://doi.org/10.1093/acprof:oso/9780199570959.003.0013
Smith, Garrett & Franck, Julie & Tabor, Whitney. 2021. Encoding interference effects support self-organized sentence processing. Cognitive Psychology 124. 101356. DOI: http://doi.org/10.1016/j.cogpsych.2020.101356
Stark, Elisabeth. 2014. Frequency, form and function of cleft constructions in the Swiss SMS corpus. In De Cesare, Anna M. (ed.), Frequency, forms and functions of cleft constructions in romance and germanic: Contrastive, corpus-based studies, trends in linguistics, 325–344. Mouton de Gruyter Berlin, Munich & Boston. DOI: http://doi.org/10.1515/9783110361872.325
Tily, Harry & Frank, Michael & Jaeger, Florian. 2011. The learnability of constructed languages reflects typological patterns. In Proceedings of the 33rd annual conference of the cognitive science society (cognitive science society, austin, tx).
Tomasello, Michael. 2009. The usage-based theory of language acquisition. In Bavin, Edith L. (ed.), The cambridge handbook of child language, 69–87. Cambridge: Cambridge University Press. DOI: http://doi.org/10.1017/CBO9781316095829.005
Van den Steen, Katleen. 2005. Cleft constructions in French and Spanish. In Delbecque, Nicole & van der Auwera, Johan & Geeraerts, Dirk (eds.), Perspectives on variation: sociolinguistic, historical, comparative, 275–290. Berlin & New York: Mouton de Gruyter.
Villata, Sandra & Rizzi, Luigi & Franck, Julie. 2016. Intervention effects and relativized minimality: New experimental evidence from graded judgments. Lingua 179. 76–96. DOI: http://doi.org/10.1016/j.lingua.2016.03.004
Warren, Tessa & Gibson, Edward. 2002. The influence of referential processing on sentence complexity. Cognition 85(1). 79–112. DOI: http://doi.org/10.1016/S0010-0277(02)00087-2
Wilcox, Ethan & Levy, Roger & Morita, Takashi & Futrell, Richard. 2018. What do rnn language models learn about filler-gap dependencies? arXiv preprint arXiv:1809.00042. DOI: http://doi.org/10.18653/v1/W18-5423
Yang, Charles. 2016. The price of linguistic productivity: How children learn to break the rules of language. Cambridge MA: MIT press. DOI: http://doi.org/10.7551/mitpress/9780262035323.001.0001
Yang, Charles & Crain, Stephen & Berwick, Robert C. & Chomsky, Noam & Bolhuis, Johan J. 2017. The growth of language: Universal Grammar, experience, and principles of computation. Neuroscience & Biobehavioral Reviews 81. 103–119. DOI: http://doi.org/10.1016/j.neubiorev.2016.12.023
Zeldes, Amir. 2017. The GUM corpus: Creating multilayer resources in the classroom. Language Resources and Evaluation 51(3). 581–612. DOI: http://doi.org/10.1007/s10579-016-9343-x
Zeman, Daniel & Nivre, Joakim & Abrams, Mitchell. 2020. Universal Dependencies 2.6. LINDAT/CLARIAH-CZ digital library at the Institute of Formal and Applied Linguistics (UFAL), Faculty of Mathematics and Physics, Charles University. http://hdl.handle.net/11234/1-3226.
Zipf, George K. 1949. Human Behavior and the Principle of Least Effort. Boston: Addison-Wesley.