
1 Introduction
A long-standing body of syntactic research has fruitfully explored the hypothesis that complex words are derived as part of syntactic computations (see Baker 1988; Li 1990; Lasnik 1995; Marantz 1997; Ackema & Neeleman 2004; Kornfilt & Whitman 2011; Bobaljik 2017; Starke 2010; 2018). Syntax involves the computation of syntax-semantics features into abstract morphemes constituted by feature bundles which are externalized in the late insertion of vocabulary items that include phonological expressions and conditions for insertion (Halle and Marantz 1993; Starke 2010; Svenonius 2012). In Distributed Morphology (DM) (Halle & Marantz 1993), vocabulary items can be inserted when their specifications contain a subset of the grammatical features in the syntactic representation. Insertion is excluded when the vocabulary item contains specifications of features that are not present in the syntactic representation. Where several subset vocabulary items could be inserted, a selection criterion requires that the item specified for the greatest number of features represented in syntax be selected in accordance with the Elsewhere Principle (see the Subset Principle of DM) (Halle 1997; Embick & Noyer 2007). In contrast, in Starke’s (2010; 2018) Nanosyntax (NS), vocabulary items containing a superset of the features on the syntactic representation (the Superset Principle) are candidates for insertion. Insertion is excluded when the vocabulary item is not specified for all the features in the syntactic representations. Where several items meet the superset condition for insertion, a selection criterion requires that the item with the fewest features unspecified in the structure be selected, under the general principle “minimize junk”, as a general prohibition against unnecessary/unwarranted information (Starke 2010: 4).
We consider the psychological processes whereby vocabulary items spell out features of syntactic nodes in adherence to the Subset Principle of DM:
“Subset Principle – the phonological exponent of a Vocabulary Item is inserted into a position if the item matches all or a subset of the features specified in that position. Insertion does not take place if the Vocabulary Item contains features not present in the morphemes. Where several Vocabulary Items meet the conditions for insertion, the item matching the greatest number of features must be chosen (Halle, 1997).” (Embick & Noyer 2007: 7).
We consider third person subject-verb agreement in the French future tense paradigm including the third-person vocabulary items -a (3ps.sg) and -ont (3ps.pl) as in mange+r+a (eat-fut.3ps.sg) vs. mange+r+ont (eat-fut.3ps.pl), differing in the feature specifications [Number: Ø] vs. [Number: Plural]. In deriving Les enfants mangeront ‘the children will eat-plural’, the vocabulary items -a (3ps.sg) and -ont (3ps.pl) constitute therefore alternative agreement realizations. The insertion condition allows vocabulary items specified for [Number: Ø] (singular) and [Number: Plural] (plural) as insertion candidates in the externalization of a node including [Number: Plural]. However, only the candidate that most closely matches the [Number: Plural] specification in the syntactic computation can be selected for insertion, as per the selection criterion, in accordance with the Elsewhere Principle, in which a more specified item should be selected over a more general one (Anderson 1969; Kiparsky 1973; Halle & Marantz 1993; among others). Given that the specification [Person: Participant], which is required for first or second person, is absent from the syntactic computation for a third-person subject, vocabulary items specified for this feature will not be called upon for insertion in DM. In the derivation for L’enfant mangera ‘the child will eat-singular’, only the vocabulary item -a is a possible candidate to the exclusion of -ont in DM. NS assumes exactly the opposite insertion condition: in the derivation for L’enfant mangera ‘the child will eat-singular’ the vocabulary items for -a and -ont are part of the possible candidates as supersets of the agreement features in syntax. This induces a comparative selection from a set of partially ordered alternatives in which the smallest specification is selected following a general prohibition against unnecessary information. In the derivation for Les enfants mangeront ‘the children will eat-plural’, -a is excluded from insertion since the superset condition is not met.
We note that the DM approach to late insertion seems to reduce to basic cognitive processes. The Subset Principle reduces to content-based access to vocabulary items. In content-based access, the computations of syntactic representations coactivate shared specifications for vocabulary items (Berwick & Chomsky 2016). The computation of an inflectional node for the French future tense bearing [Number: Plural], therefore, automatically activates -a with specifications including [Number: Ø] as well as -ont involving [Number: Plural]. Crucially, multiple activations create a partial order based on feature-specifications. This partial order defines an information scale <-ont, -a> in which more specific plural -ont carries more information than -a does. We propose that, in the context of an activated Plural-marked -ont, the vocabulary item -a receives a [–Plural] (“not -ont”) interpretation.1 Scalar reasoning is well documented in other areas of language use, such as conventional implicatures (Horn 1972; 1978; 1989) and presuppositions (Heim 1991; Sauerland 2007). It is induced by a general principle to maximize the information provided. We note that it naturally extends to vocabulary selection. When the inferred [–Plural] default value is induced for [Number: Ø], -a becomes unsuitable for insertion—since the -a vocabulary item with this added information mismatches the syntactic representation. The -ont vocabulary item must then be selected. Assuming feature underspecification, the Subset Principle of DM seems therefore to follow from independently motivated general cognitive processes, including the involvement of conceptual processes of inference. We note that the Superset Principle of NS is compatible with activation spreading along feature structures. In superset activation, vocabulary items are also partially ordered according to the feature sets that they encode. The item with the smallest specifications is maintained while the rest are pruned. The pruning of ranked alternatives takes place as these alternatives are inferred to be non-optimal candidates in the externalization of the subset syntactic representation, under the general prohibition against unnecessary information in language use. This general prohibition against unnecessary information could be seen as a corollary to information maximization. Such lower and upper bound conditions on informativity are not new in language use. Thus, in Grice’s (1975) treatment of conversational implicatures in adherence to a general principle of cooperation, the maxim of quantity dictates that contributions to discourse be as informative as required but not more informative than is required. Likewise, in the externalization of structure, the comparative selection of the best candidate from a set of partially-ordered alternatives induced by a syntactic representation should also adhere to general principles governing informativity in communication.
The degree of specificity of the information seems to crucially interact with processes of memory and attention to explain number attraction phenomena in which a closer plural noun phrase (but not a singular noun phrase) induces a subject-verb agreement mismatch in production (Bock & Miller 1991; Chanquoy & Negro 1996; Franck, Vigliocco, & Nicol 2002; among many others). Intervention patterns are also found in processing (Nicol, Forster, & Veres 1997; Pearlmutter, Garnsey, & Bock 1999; Wagers, Lau, & Phillips 2009). Likewise, Wagers and McElree (2011) showed that the plural is more readily preserved than the singular in conditions of processing demands. Wagers and McElree (2011) suggest that the lexically specified [Plural] receives the focus of attention and therefore is maintained. We argue here that a [Number: Ø] representation saves on the cost of storage and processing load in domain-specific computations. It, however, enables the coactivations of vocabulary items -a with [Number: Ø] and -ont with [Number: Plural] specifications by a computation including [Number] and [Plural]. This predicts specific interactions between comparative vocabulary selection and conceptual-structure processing in the absence of direct interface relations between agreement and conceptual structure, given that inferential processes are conceptual processes.
Our argument makes four central theoretical points i.) that there are different processes involved in the retrieval of vocabulary items in a third person singular vs. plural agreement context, ii.) that these procedural differences rely on representational underspecification, iii.) that they involve the interaction of domain-specific computations in access to vocabulary items with domain-general processes in comparative selection of the best candidate among partially ordered alternatives, and iv) that subset vs. superset models make distinct empirical predictions about the interaction of domain-specific vocabulary access with the comparative selection of the most informative candidate by domain-general processes. We organized our paper as follows: first, we detail the processes in the morphosyntactic processing of the French future tense in DM, with NS comparisons. We outline a methodology based on error detection with experimental predictions for basic cognitive processes instantiating subset and superset vocabulary access models, introducing research questions and hypotheses. After presenting the study, we report on a specific interaction between singular number agreement mismatch and picture-probe classifications in two modalities. We argue that these follow from the involvement of conceptual processes as a representationally compatible singular (subset) item is determined to be inappropriate for a plural context, but not vice versa. We examine the degree to which experimental results could be explained by other differences, arguing that this specific interaction between agreement and conceptual-structure processing is unexplained by superset models of late insertion, or by interface relations, frequency, information load, and phonological cohort activation.
2 Feature-based vocabulary item selection
We illustrate feature-based access to vocabulary items in the computation of the French future tense sentences Les enfants mangeront (The children will-eat-plural) (Figure 1) and L’enfant mangera (The child will-eat-singular) (Figure 2), assuming a basic Minimalist representation. The future inflection for 3rd person plural in /mɑ̃ʒ(ə)+ʀ+ɔ̃T/ (eat-fut.3ps.pl) involves a verbal root morpheme marking futurity on the v head together with an agreement morpheme associated with number inflection for the future stem. First, as Figure 1 shows, syntax computes the root √Mange ‘eat’ (externalized as /mɑ̃ʒ(ə)/) with its v category, with values uTense: Future* (externalized as /-ʁ/). In v-to-T raising (Pollock 1989 inter alia), the computation of the v-node with the T node derives an abstract syntactic representation for the agreeing verb form /mɑ̃ʒ(ə)+ʀ+ɔ̃T/ (eat-fut.3ps.pl). In content-based access, the syntactic computation in Figure 1 activates terminal vocabulary items based on shared features with the syntactic morphemes at spell-out. It enables the coactivation of compatible vocabulary items. As all formal requirements for the T-domain have been satisfied, the structure [[√MANGE ] v ] activates the vocabulary item in (1); the structure [v: uTense: Future] activates the vocabulary item in (2); and the structure [T: uPerson: Ø, uNumber: Plural] activates the vocabulary items in (3) and (4).
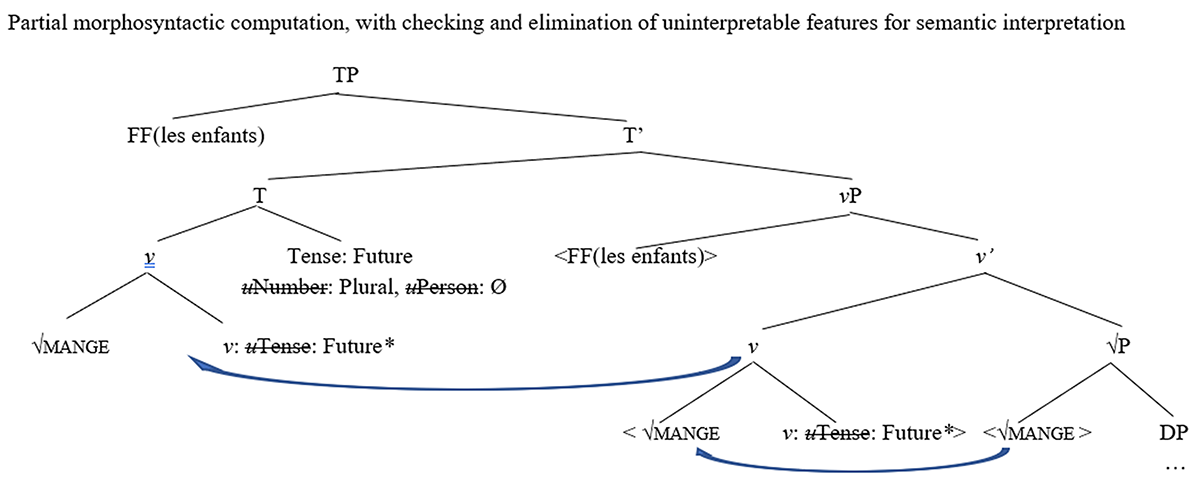
Derivation for les enfants mangeront… ‘the children will eat….’
Note: FF(les enfants) specifies the set of formal features (FF) defining the expression les enfants ‘the children,’ including semantically interpreted referential features. The diacritic * indicates a local domain for feature checking. <x> marks a silent copy of x. uF marks an uninterpretable (agreement) feature F. uF indicates that the uninterpretable feature was checked and deleted given that only interpretable features can exist at the semantic interface by the principle of Full Interpretation.
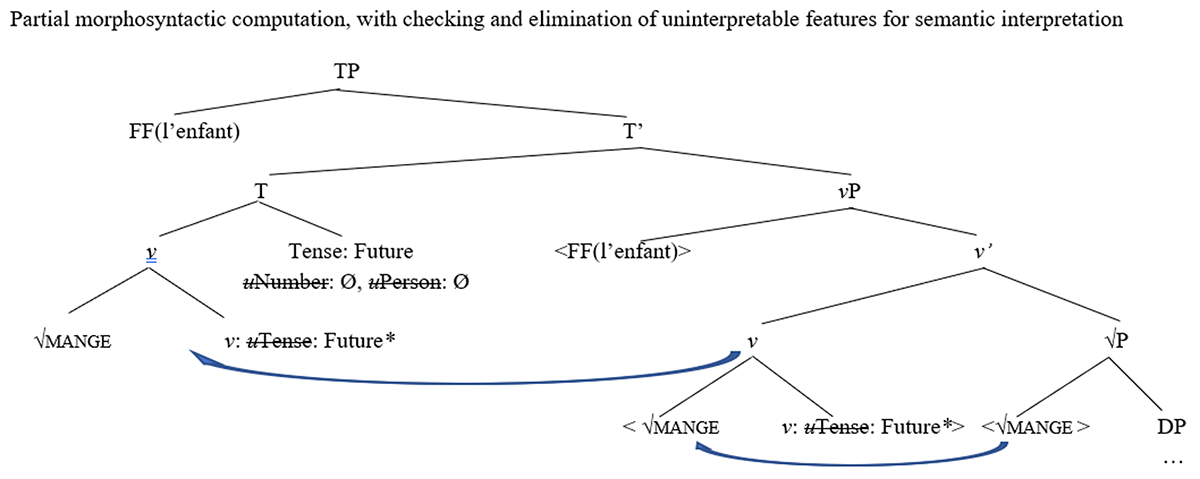
Derivation for l’enfant mangera… ‘the child will eat….’
| (1) | /mɑ̃ʒ(ə)/ | ↔ | [[√mange ] v ] |
| (2) | /-ʁ/ | ↔ | [v: uTense: Future] / root _________ root = {… √mange …} |
| (3) | /-a/ | ↔ | [T: uPerson: Ø, uNumber: Ø] / [v: uTense: Future] _________ |
| (4) | /-ɔ̃T/ | ↔ | [T: uPerson: Ø, uNumber: Plural] / [v: uTense: Future] _________ |
Coactivation leads to the automatic activation of the vocabulary items in (3) and in (4), since the specifications of features of both (3) and (4) are also in the syntactic representation. (3) and (4) are therefore both candidates for externalization. Crucially, the items -as (2ps.sg) (5), -ez (2ps.pl) (6), -ai (1ps.sg) (7), and -ons (1ps.pl) (8) are not activated with Participant and Author not in the computation.2
| (5) | /-aZ/ | ↔ | [T: uPerson: Participant: Ø, uNumber: Ø] / [v: uTense: Future] |
| (6) | /-eZ/ | ↔ | [T: uPerson: Participant: Ø, uNumber: Plural] / [v: uTense: Future] |
| (7) | /-e/ | ↔ | [T: uPerson: Participant: Author, uNumber: Ø] / [v: uTense: Future] |
| (8) | /-ɔ̃Z/ | ↔ | [T: uPerson: Participant: Author, uNumber: Plural] / [v: uTense: Future] |
The vocabulary items in (3) and (4) are, however, partially ordered with respect to each other on an informational scale <-ont, -a>, determined by feature structure, in which -ont is more specified/informationally richer than -a. As is generally the case in scalar reasoning (see Horn 1972; 1978; 1989 for conventional implicatures and Heim 1991; Sauerland 2007 for presuppositions), the selection of informationally weaker (3) over (4) implicates that (4) is not warranted. Hence, the less informative item with the underspecified value (i.e. [Number: Ø]) negates the more informative item with the specified value (i.e. [Number: Plural]) as an inference is induced by a general principle of information maximization (see Heim 1991).3 The specification [Number: Ø] is contexually interpreted as [Number: -Plural] on the <-ont, -a> scale.4 This real-time [–Plural] inference obtained from the absence of the [Plural] specification makes (3) ineligible for insertion. The selection of the item with the greatest number of specifications matching the features in the syntax is implemented by eliminating less specified vocabulary items.
Hence, the elimination of (3) with underspecified [Number: Ø] in the context of an activated (4) with the specification [Number: Plural] can reduce to a scalar inference on the information scale defined by the [Number: Ø/Plural] feature structure. Scalar relations play a central role in language use: For truth conditions, or is exclusive in its scalar relation with stronger and. For presuppositions, indefinite a is non-unique in its scalar relation with stronger the (Heim, 1991). Across domains, therefore, the maximization of the information guides selection among alternatives. Feature-based coactivation crucially establishes scalar relations, enabling information maximization to guide externalization. The coactivation of vocabulary items by syntactic computations in content-based retrieval together with general conditions on word selection in language use therefore derives the insertion and selection conditions of the Subset Principle. Scalar reasoning therefore offers a mechanism for form selection whereby “where several Vocabulary Items meet the conditions for insertion, the item matching the greatest number of features must be chosen (Halle 1997)” (Embick & Noyer 2007: 7).
Given the computation in Figure 2, in content-based access, the agreement morpheme with [Number: Ø] will not activate the vocabulary item -ont (3ps.pl) as in (4), since there is no Plural value on the node that would coactivate a vocabulary item with the specification [Number: Plural]. Therefore, vocabulary item -ont (3ps.pl) cannot be accessed by this computation in coactivation. No information scale <-ont, -a> thus participates in the selection of the vocabulary item -a (3ps.sg) in L’enfant mangera.
| (3) | /-a/ | ↔ | [T: uPerson: Ø, uNumber: Ø] / [v: uTense: Future] _________ |
| (4) | /-ɔ̃T/ | ↔ | [T: uPerson: Ø, uNumber: Plural] / [v: uTense: Future] _________ |
Hence, given the mechanism described above to illustrate the derivation of L’enfant mangera vs. Les enfants mangeront, we now turn to the processing of ungrammatical items *L’enfant mangeront (the child will eat-pl) vs. *Les enfants mangera (the children will eat-sg). It is first claimed (claim 1) that errors such as *L’enfant mangeront (the child will eat-pl) vs. *Les enfants mangera (the children will eat-sg) will have significantly different psycholinguistic status as a result of feature underspecification. It is additionally claimed (claim 2) that these errors involve distinct processes in content-based access and comparative selection implemented through domain-general elimination mechanisms respectively.5 Thus, detecting that mangera is inappropriate in a plural context, as a violation of the selection criterion requires the real-time scalar inference [–Plural], as a conceptual process. Detecting that mangeront is inappropriate in a singular context does not as, per the insertion condition, this form has never been activated in content-based access. The insertion condition and selection criterion of the Subset Principle are thus due to independent psychological mechanisms, given a hierarchical organization of feature specifications in vocabulary items. Crucially therefore, on our model, the entire paradigm is not accessible in computing L’enfant mangera (The child will-eat-singular) and Les enfants mangeront (The children will-eat-plural).6 Thus, even though the French paradigm includes quasi-homophonous forms (e.g. /-aZ/ (2ps.sg) vs. /-a/ (3ps.sg), /-ɔ̃T/ (3ps.pl) vs. /-ɔ̃Z/ (1ps.pl), these vocabulary items are not called upon since they include specifications that are not part of the node requiring 3rd person agreement.7
Our embedding of DM into more basic cognitive processes suggests that DM can be empirically distinguished from NS in terms of processes of vocabulary-item access by syntactic computations and general processes of selection from a partially ordered set. Given the specifications of vocabulary items in (3)–(8), the NS-based derivation of L’enfant mangera (The child will-eat-singular) would include superset access to the entire paradigm (3)–(8), whereas the derivation of Les enfants mangeront (The children will-eat-plural) would include superset access to half of the paradigm (4), (6), and (8), with pruning of unnecessary information. Hence, morphological errors such as *L’enfant mangeront (the child will eat-pl) will meet the compatibility condition of NS, whereas errors such as *Les enfants mangera (the children will-eat-singular) will not, since the specification [Number: Ø] for -a does not include the syntactic representation [Number: Plural]. NS, therefore, also predicts two types of errors, in terms of compatibility condition and selection criteria. However, the characterization of singular vs. plural verb form errors in subject-verb agreement is completely different. Superset alternatives constitute a partially-ordered set generating information scales. However, pruning is rather based on the avoidance of unnecessary/unwarranted information (Starke 2010). This is a natural corollary to maximize information. Thus, the detection of the mismatch error *L’enfant mangeront (the child will eat-pl) arises as the vocabulary item -ont with a [Number: Plural] specification resides on a scale with vocabulary item -a with the specification [Number: Ø] matching the syntax, so that the specification [Plural] is inferred as unwarranted, since -ont includes more information than strictly necessary. From a cognitive standpoint, both models, therefore, rely on domain-specific vocabulary activations and comparative processes of item selection from a set of partially ordered alternatives. The design of DM, consistent with content-based access to vocabulary items, avoids the activation of vocabulary items with unused features. It seems thus conceptually preferable. We argue, however, that the precise interaction of domain-specific vocabulary activations and domain-general comparative processes of item selection from a set of partially ordered alternatives can empirically distinguish between subset and superset access models.
3 The study
We argued that the Subset Principle of DM with insertion and selection conditions can be profitably seen as following from basic cognitive processes: content-based access in feature coactivation by syntactic computations and conceptual processes of scalar inference that enable the selection of the most informative item from a set of alternatives ordered on an information scale. Turning to our search for empirical evidence, we adopt the working hypothesis that singular verb forms in mismatch involve (proper subset) selection errors whereas plural verb forms involve (unactivated) insertion errors, so that singular vs. plural verb form errors crucially involve failures to adhere to domain-general conceptual processes vs. domain-specific computations respectively. This failure to adhere to processes of inference is assumed to create a measurable processing load, as the processing system must reevaluate the selection when a mismatch is found.
The converse hypothesis (null hypothesis) is provided by a process-based implementation of NS in which singular and plural verb forms in mismatch also involve different error types; however, their nature in terms of activation and comparative processes of selection from a set of partially ordered alternatives is diametrically opposed to DM. In NS, the singular verb form error constitutes an (unactivated) insertion error and the plural verb form error constitutes a (proper superset) selection error. Hence, in NS, singular verb form errors involve a failure to adhere to domain-specific vocabulary item activation and plural verb form errors involve a failure to adhere to processes of pruning of unncessary information in a partially-ordered set.
Each theory predicts different effects for the illicit access to an item and for the illicit retrieval of a form among a set of partially ordered alternatives. In both DM and NS models, it is expected that the comparative selection of the most informative item from a group of morphosyntactically licensed partially-ordered set of alternatives might be more onerous on general cognition than automatic access by the syntactic computation. Indeed, in both DM and NS models, comparative selection involves inferences derived on an information scale induced by syntactically-activated vocabulary items, in adherence to general principles governing the representation of information in language.
Crucially, the plural form mangeront (eat-fut.3ps.pl) and the singular form mangera (eat-fut.3ps.sg) do not differ semantically: both encode the concept mange ‘eat’. In activation spreading, mange ‘eat’ activates semantically related concepts such as sandwich in its semantic neighborhood. Activation spreading provides context in the ongoing representation of the sentence meaning. Because number agreement has no semantic function, no interface relation is implicated on acount of morphological agreement.8 However, in our process-based embedding of DM and NS models of late insertion, a highly specific interaction between error types and conceptual processing in the ongoing construction of the sentence meaning is predicted in error detection. This is precisely because the automatic feature-based access to specifications of vocabulary items by the syntactic computation is domain specific, whereas the comparative selection of the most informative option from a set of partially ordered alternatives involves cross-domain conceptual structure processes. The DM and NS models differ only in the distribution of the interaction between error-types and conceptual structure in the task of error detection.
Hence, given subset-based activation and selection as in DM in the context of subject-verb agreement mismatch, the detection that mangera is illicit in a syntactic context with [Number: Plural] requires a <-ont, -a> scale enabling a [–Plural] inference. The competition-based detection of mangera in *Les enfants mangera (the children will eat-sg) predicts an interaction with conceptual-structure processing of the ongoing construction of the sentence. No such comparative inference arises with an illicit plural mangeront in a singular context: superset mangeront was never activated by the syntax. NS makes the opposite prediction. The detection that mangeront is illicit in *L’enfant mangeront (the child will eat-pl) requires a partially ordered set of alternatives, in which the specification [Number: Plural] for -ont on a scale with the specification [Number: Ø] for -a matching the syntax is inferred to be unnecessary under a general principle of prohibition against unwarranted information. Comparative selection on a scale engages domain-general cognition. In NS, detecting the ungrammaticality of mangera in *Les enfants mangera (the children will eat-sg) will not engage general reasoning. The vocabulary item was never activated by the syntaction computation.
In order to provide empirical evidence for an interaction between morphosyntactic processing and conceptual processing, we examined picture-probe classification times across grammatical and ungrammatical stimuli involving the two types of errors. Thus, we examined relative reaction times as a picture of a sandwich was classified as [–human] when presented immediately after the verb in subject-verb agreement match or mismatch, either as the stimuli were heard or read. Respondents indicated grammaticality judgments at the end of each sentence. As a conceptual decision, the classification of an object as [–human] calls for inferences where [–animate] entails the exclusion of human entities, as human entities represent a subset of animate entities. We expect significant interactions between processes as an error is detected, since an error requires additional attention to processes, with increased focus of attention of the inferred [–Plural] value. Following our working hypothesis based on DM, it was therefore predicted that picture-probe classification times would take longer after a singular verb form in a plural context than after the verb in all other conditions, whether the stimulus was presented orally or in writing, as picture classification processes would compete for resources as a subset singular verb form is found to be inelligible for insertion via a [–Plural] scalar inference in comparative selection. On the converse hypothesis based on NS, it would be predicted that picture-probe classification times would take longer after a plural verb form in a singular context than after the verb in all other conditions. This should also be independent of the modality of stimulus presentation.
3.1 Research questions and predictions
Two related research questions (RQs) addressed our process-based model of vocabulary item selection in adherence to the Subset Principle. The central reseach question (RQ1) addressed our working hypothesis of a general scalar inferential process in comparative form selection. This inferential process fleshes out underspecified vocabulary item information on a scale, leading to the elimination of less specified insertion candidates for a node. RQ1 therefore asks: Will picture-probe classification times take longer after the singular verb form mangera as opposed to the plural verb form mangeront in subject-verb agreement mismatch? Given the subset coactivation of vocabulary items by the syntactic computation and general scalar inferential processes at play in comparative form selection, it is expected that it will take longer to classify the same picture after the singular form mangera in mismatch. On our working hypothesis, this effect will not be replicated with the mismatching plural form mangeront, as domain-general general cognition is not involved in identifying this mismatch (prediction 1). On the converse hypothesis offered by NS, the exact opposite pattern is expected. Picture-classification times would take longer after mistmatching plural form mangeront.
A second research question addressed externalization as a process involving syntactic feature structure rather than phonetic or orthographic properties of the signal. RQ2 therefore asks: Will there be an effect of aural vs. visual modality of stimulus presentation? Under conditions of reduced capacity, similar results should be obtained across written and aural modalities, because the predicted effects are due to feature-based computations feeding processes of inference and not to external realizations of vocabulary items in either sound or writing (prediction 2).
3.2 Stimulus and tasks
The study consisted of two experimental tasks involving picture-probe classifications in the context of grammatical and ungrammatical stimuli as in (9a–d), administered aurally and in writing. In the aural task, respondents listened to stimuli via headphones and provided a grammaticality judgment after each sentence. While they were listening, respondents classified picture probes as [±human]. Each item contained one picture probe to be classified. In the experimental items, the picture probe was presented immediately after the verb. This task was therefore bimodal. In the written task, subjects read the same stimuli out loud at a predetermined forced pace (Dekydtspotter & Miller 2013; Miller 2014), and again provided a grammaticality judgment after each item. They classified the same pictures as [±human]. This task was therefore unimodal. Results obtained under unimodal and bimodal modalities of stimulus presentation should echo each other if feature structures (rather than orthographic and/or phonological representations) constitute the primary vectors of grammatical behavior.
Stimuli included 40 critical items as in (9a–d), and 66 distractors covering a range of structures. Critical items were organized in ten quadruples as in (9a–d), including two grammatical items (9a,b) and two ungrammatical items (9c,d) resulting from a morphological mismatch in number between the subject and the agreement morphology on the verb. The error in (9c) involves a singular verb form that does not externalize all the features on the plural syntactic node (a subset vocabulary item). In contrast, the error in (9d) involves a plural verb form that signals a number value not represented on the syntactic node (a superset vocabulary item).
- (9)
- a.
- Demain,
- tomorrow
- l’enfant
- the child
- ne
- neg
- mangera [PIC]
- eat-fut.3ps.sg
- pas
- neg
- beaucoup
- a lot
- de
- of
- desserts.
- desserts
- b.
- Demain,
- tomorrow
- les
- the
- enfants
- children
- ne
- neg
- mangeront [PIC]
- eat-fut.3ps.pl
- pas
- neg
- beaucoup
- a lot
- de
- of
- desserts.
- desserts
- c.
- *Demain,
- tomorrow
- les
- the
- enfants
- children
- ne
- neg
- mangera [PIC]
- eat-fut.3ps.sg
- pas
- neg
- beaucoup
- a lot
- de
- of
- desserts.
- desserts
- d.
- *Demain,
- tomorrow
- l’enfant
- the child
- ne
- neg
- mangeront [PIC]
- eat-fut.3ps.pl
- pas
- neg
- beaucoup
- a lot
- de
- of
- desserts.
- desserts
- ‘Tomorrow, the child/ the children will not eat (3sg/pl) a lot of desserts.’
Picture-probe classification tasks have been used to investigate conceptual-structure processing loads, including syntax-linked concept activation in sentence comprehension (see Felser & Roberts 2007; Love 2007; Roberts, Marinis, Felser & Clahsen, 2007; Dekydtspotter & Miller 2013; Miller 2014; 2015; Dekydtspotter & Farmer 2016). We extend this technique beyond processes of comprehension to processes involved in form selection that do not involve the syntax-semantics interface. Thus, picture probes were presented after each verb form in critical stimuli as in (9a–d). Probes always bore the same conceptual structure relations with the verb across the four conditions. The same picture was used in each quadruple, so that any semantic priming effect from the verb would be constant. Crucially, there was always intervening material between the verb/picture and the direct object in each critical item. As one can see in item 9, pas beaucoup de (not a lot of) appears between the verb and desserts (dessert-plural). This choice was made to ensure that only the verb form would have an effect on picture classifications, as the participants classified the picture immediately as it appeared on the screen, thus before reading or listening to the direct object mentioned in the critical items (e.g. desserts – desserts (9)). Any difference in picture-probe classification times obtained would therefore be linked only to the specific verb agreement morphology in the syntactic context provided by the sentence. Picture-probe classification time differences could therefore reveal a possible interaction between vocabulary item selection and general processes of inference in conceptual structure. This is because a picture classification task should not involve any linguistic processing, whereas it would clearly involve domain-general conceptual processes.9
In all critical items, the subject was vowel-initial, to provide the same cues of liaison and elision across items. These cues were selected as providing robust segmental information about number both orally and in writing. Elision constitutes “the phonetic absence of otherwise pronounced final vowels before vowel initial words” (Tranel 1996: 433). Liaison constitutes “the pronunciation of otherwise silent word-final consonants before vowel initial words” (Tranel 1996: 433). All the critical items were in the futur simple (simple future). This choice was made to have an entirely regular paradigm, since the stem is always the same and the only alternation would be in the ending. In addition, for the specific verbs we selected, the stem was always the infinitive, so that no irregularity could have induced more processing cost for some verbs but not others. The distractors contained a variety of grammatical errors, such as gender agreement errors, missing or erroneous preposition use, lack of required suppletive morphology, and included verb conjugation errors. Their main verb was also in the future tense. They also included quasi-repetitions. This was done so that distractors and critical items appeared similar. The task felt seamless to respondents. The critical items are provided in Appendix 1. One item per block is provided for space reasons. Hence, the subject and the verb are always in the singular.
Both tasks were presented using the DMDX software (Forster & Forster 2003). For the listening task, the items were recorded by a French male native speaker, reading aloud at a comfortable speed. Participants listened to the stimuli with headphones. In the reading task, the respondents themselves read the items out loud at a comfortable volume. Sentences were presented word by word in the middle of the screen at a pre-determined speed. A one-letter word was presented for 416 ms, and each additional letter took 16.66 ms. This approaches the average listening time for singular and plural verbs. Participants were monitored for fluent reading to ensure that they were processing what they were reading. Across these presentations, the picture probes flashed on the screen for 500 ms. This speed was selected to ensure sufficient processing demand. Presentation speeds are standardly manipulated to affect processing load (McDonald 2006; Hopp 2010; López Prego & Gabriele 2014). The speed selected for the written task very closely approached the speed on the listening task. Considering the presentation of the crucial verb segment, the mean duration in the written stimuli of singular (506 ms) and plural (539 ms) verb forms differed on average by 40 ms from the mean duration in the oral stimuli of singular (457 ms) and plural (510 ms) verb forms.10 Indeed, it takes about 50 ms for visual information to reach the phonological representation in the auditory cortex (Traxler 2011: 376). Thus, a slightly longer presentation of the stimulus in the written task as opposed to the aural task was necessary.
In critical items, the picture probe always appeared immediately after the verb. It always represented an object semantically related to the verb.11 For instance, after mangera/mangeront a picture of a sandwich appeared. In critical items, these picture probes were always inanimate. The distractors contained both pictures of animate ([+human]) entities and objects, so that the total number was half [–human] and half [+human]. The position of the picture varied in the distractors. While reading/listening to each item, the participants classified each picture immediately after seeing it on the screen using the right arrow to indicate that it was [+human] and the left arrow to indicate its [–human] status. They were instructed to do that as fast as possible after seeing the picture, using their right hand. At the end of each sentence, the participants pressed Y if the sentence they heard/read was grammatical and N if what they heard/read was ungrammatical, using their left hand. Therefore, two measures were always taken: picture classification times and grammaticality judgments.
3.3 Procedures and participants
The listening task and the reading task involved 19 native speaker participants each. They received a small monetary compensation for their participation. Each participant was tested individually in a quiet room. After consent procedures approved by the institutional review board, they filled out a background questionnaire and performed the main task, in the listening or reading modality. Participants in the listening modality were university students studying in the USA, recruited in the United States, and university students recruited in Northern France. Seventeen participants were from France. Two were from Belgium and Switzerland respectively. Participants in the reading task were all university students from Northern France. The average age for the group recruited for the listening task was 29.53 (range 18 to 41). The average age for the group recruited for the reading task was 22.63 (range 18 to 29).
3.4 Analytical procedures
Both the data from the reading task and the data from the listening task contained a few missing values: 0.79% for the listening task and 1.7% for the reading task. For both modalities, the raw reaction times (RTs) in picture-probe classifications obtained in milliseconds were transformed into Log RTs for statistical purposes. The data were cleaned by subject and by condition. Values above and below two standard deviations of the mean were replaced with the maximum and minimum values allowed, respectively. This resulted in a replacement of 2.41% of the data obtained for the listening task and 2.63% of the data obtained for the reading task. These procedures are standard (e.g. Nicol, Forster, & Veres 1997). The accuracy on picture classifications was close to ceiling, therefore all the data was used for analysis. Accuracy on picture classifications was 98.16% for the reading task and 98.29% for the listening task.
Both tasks involved two data points: the picture classification times and grammaticality judgments. Picture classifications rely in part on unconscious conceptual structure processes that may share resources with processes of inference in form selection, affecting their speed when processes compete for limited resources. Grammaticality judgments involve end-of-sentence conscious judgments reliant on prior error detection resulting from morphosyntactic calculations. The quality of grammaticality judgments was operationalized in terms of d’ values which take into consideration bias and sensitivity (Macmillan & Creelman 1991). For each participant, d’ values were calculated for singular vs. plural verb forms from the Hit rate and False alarm rate. The Hit rate represents the proportion of correct responses to grammatical items, whereas the False alarm rate represents the proportion of incorrect responses to ungrammatical items. A higher d’ score indicates better error detection. The maximum 4.653 indicates 100% accuracy. Thus, the difference between the d’ score for the singular verb forms and for the plural verb forms was obtained for each participant. This d’ score difference was used as a co-variate in the analysis of the Log RTs of picture-probe classification times.
An omnibus general linear model (GLM) was run with mean Log RTs per subject and per condition as within-subject factors and modality as a between-subject factor, with d’-difference as co-variate. Hence, a participant seeing the same picture four times might be expected to gradually classify it faster. Mean Log RTs per subject and condition abstract away from this fact providing the general tendencies in picture-classification times by condition of interest here.12 We also ran an item-analysis to verify that the effects of the conditions were broadly distributed across items (see Appendix 2 for the average Log RTs by item and condition across modalities).
4 Results
Table 1 provides the mean raw RTs for picture-probe classifications per condition and task. When reading aloud, respondents took 69 ms longer to classify the same picture after a singular verb form in mismatch (775 ms) than after a correct singular verb form (706 ms). In contrast, it took 33 ms longer to classify the same picture after a mismatching plural verb form (756 ms) than after a correct plural verb form (723 ms). When listening to the items, it took the participants 48 ms longer to classify the same picture after a singular verb form in mismatch (726 ms) than after a correct singular verb form (678 ms). In contrast, picture-probe classification times were essentially flat for the plural conditions. Patterns are remarkably similar across modalities of stimuli presentation.
Mean RTs and Standard Deviations on picture classifications per condition.
Note: Listening task (n = 19), Reading task (n = 19).
| Agreement singular verb form | Error singular verb form | Agreement plural verb form | Error plural verb form | |
|---|---|---|---|---|
| Listening task | 678 (193) | 726 (223) | 691 (228) | 682 (225) |
| Reading task | 706 (93) | 775 (116) | 723 (99) | 756 (104) |
Table 2 provides the d’ average for singular and plural verb forms for each task. The participants showed the same level of accuracy for the singular and the plural.13
D’ scores for singular and plural verb forms per task.
Note: Listening task (n = 19), Reading task (n = 19).
| d’ singular verb form | d’ plural verb form | |
|---|---|---|
| Listening task | 3.586 (1.095) | 3.510 (1.020) |
| Reading task | 3.979 (0.91) | 3.978 (0.74) |
A visual representation of the results can be seen in Figures 3 and 4.
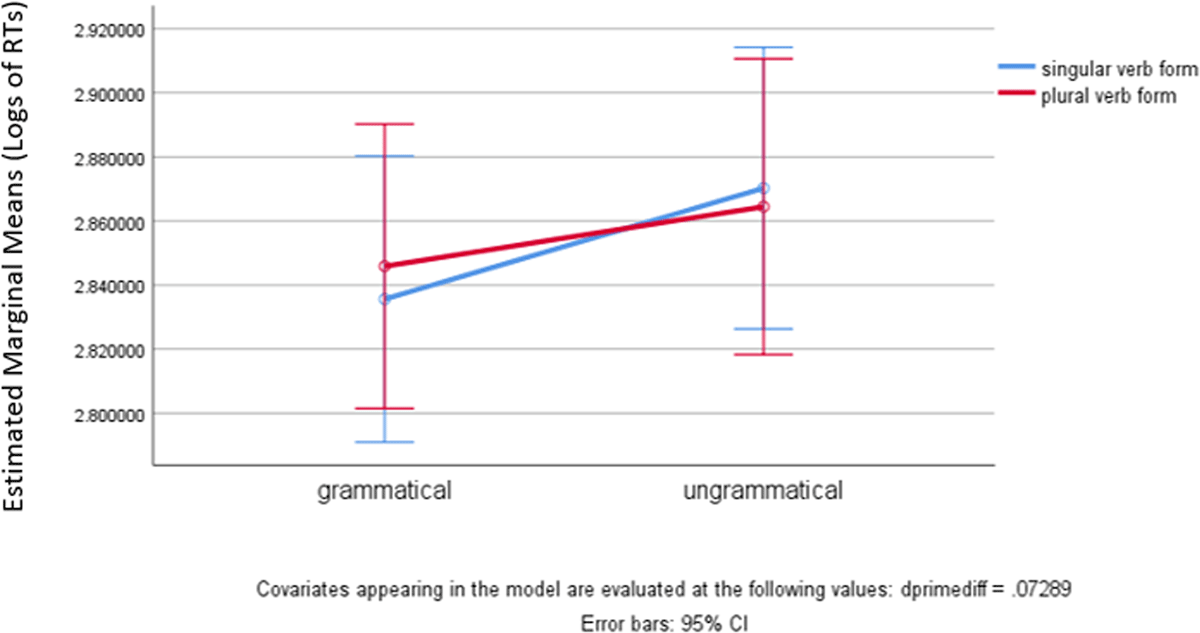
Profile of picture probe classicication times during reading.
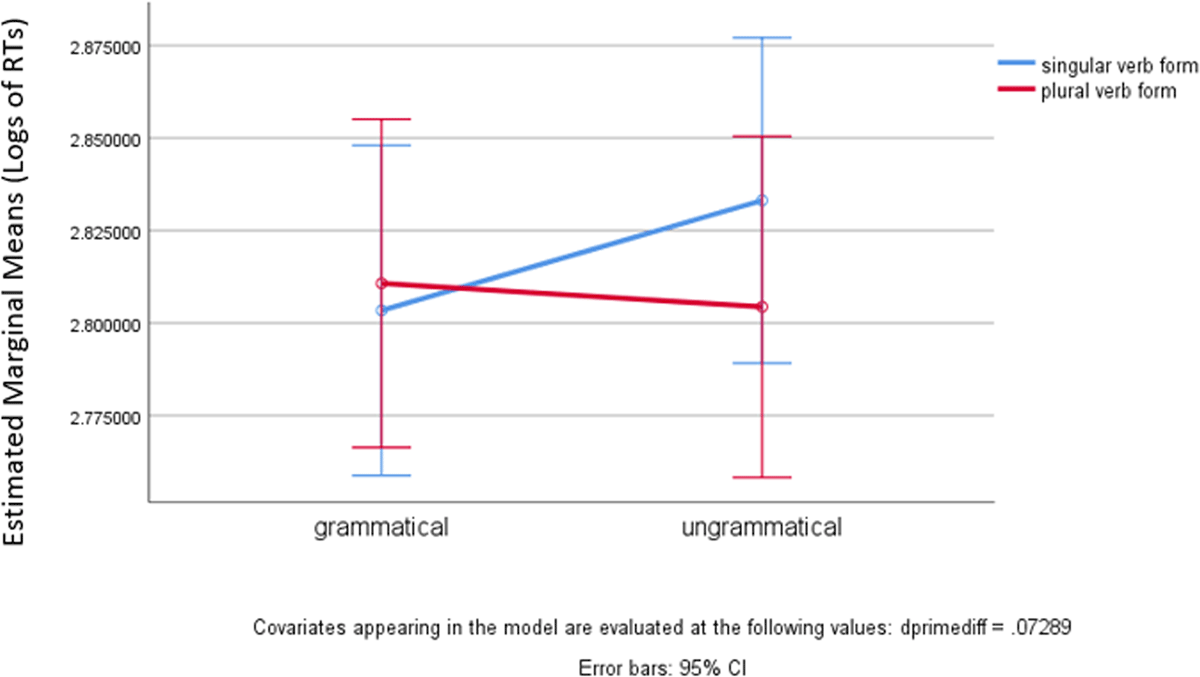
Profile of picture probe classicication times during listening.
An omnibus GLM yielded a grammaticality effect in Log RTs, F(1,35) = 12.926, p < 0.001, ηp2 = 0.270. This indicates that participants took more time overall to classify picture-probes after a verb mismatching its subject in number than after a matching verb. Crucially, a robust interaction grammaticality*form was found as well, F(1,35) = 9.564, p = 0.004, ηp2 = 0.215. This interaction shows that generally respondents were slowest in classifying picture-probes after a mismatching singular verb form. No other significant interactions were found. The d’-difference did not significantly correlate with any measures taken.14 In addition, there was no effect of modality.15 Whether the stimulus presentation was orally or in writing, the RTs to picture probes showed the same trends. An item analysis was also performed: a GLM on Log RTs with modality as inter-item factor yielded again, unsurprisingly, a grammaticality effect, F(1,18) = 18.826, p < 0.001, ηp2 = 0.511, and a robust grammaticality*form interaction as well, F(1,18) = 6.587, p = 0.019, ηp2 = 0.268. Modality did not play a role, as there was no interaction grammaticality*modality, F(1,18) = 2.854, p = 0.108, ηp2 = 0.137, or form*grammaticality*modality, F(1,18) = 0.946, p = 0.344, ηp2 = 0.05. Appendix 2 provides the average Log RTs by item and condition for both modalities combined.
In summary, a main effect of grammaticality, with increased reaction times after ungrammatical forms as opposed to grammatical forms, was further modulated by the nature of the error type. As the interaction grammaticality*form suggests, the biggest slow down in picture-probe classifications was found after a singular verb form mismatching the subject in number. This robust effect was independent of the modality of stimulus presentation. This interaction with conceptual-structure processing linked to the ongoing construction of the sentence meaning brings evidence to our working hypothesis that vocabulary item selection in late insertion relies on inferential processes of information maximization guided by feature structure, rather than on sound structure or orthography.
5 Discussion
We argued for the interaction of domain-specific computations in access to vocabulary items and domain-general comparative selection of the most informative candidate from a set of partially ordered alternatives in the retrieval of vocabulary items. Subset vs. superset access to vocabulary items make distinct empirical predictions. Hence, on our process-based implementation of DM, a singular verb form error as in *Les enfants mangera (the children will eat-sg) involves a failure to adhere to a domain-general comparative selection process, given that a singular vocabulary item is used despite its inferred [–Plural] status on a scale with a plural vocabulary item activated by the syntactic representation. In contrast, a plural verb form error in *L’enfant mangeront (the child will eat-pl) involves the failure to adhere to a domain-specific process. On our process-based implementation of NS, a singular verb form error involves a failure to adhere to a domain-specific process. In contrast, a plural verb form error involves failing to adhere to a domain-general comparative selection process of inference, given that a vocabulary item with a [Number: Plural] specification on a scale with a vocabulary item with the specification [Number: Ø] is inferred to violate the prohibition against more information than strictly necessary, given a [Number: Ø] syntactic representation.
In response to our working hypothesis, we first predicted that it would take longer to classify picture probes linked to the ongoing processing of the sentence meaning after a singular verb form error. However, this would not be replicated after a plural form error, as domain-general cognition is not involved in identifying this mismatch (prediction 1). On the converse hypothesis offered by NS, picture-probe classification times would take longer after a plural verb form error. We also predicted that similar results should be obtained across written and aural modalities, because the predicted effects rely on feature-based computations feeding domain-general processes of comparative selection rather than on external realizations of vocabulary items in either sound or writing (prediction 2).
The results aligned with these two predictions. Picture-classification times took longer after a singular verb form in a plural context, but crucially not after a plural verb form in a singular context. This pattern is fully consistent with prediction 1 of our working hypothesis based on DM, but inconsistent with domain-specific processes of vocabulary item activation and domain-general comparative selection as in NS. These picture-probe classification times were shown to be independent of oral or visual modality of stimulus presentation, consonant with our hypothesis of feature-based activation of vocabulary items.
5.1 Feature-based vocabulary selection
On our working hypothesis, processes of vocabulary selection reside in the interaction between feature-based domain-specific computations that determine the set of activated vocabulary items and domain-general processes of comparative selection on an information scale. Crucially, we argued that vocabulary item access by the syntactic computation was subset-based as in DM. In the case of the French future tense, both the vocabulary items -ont (3ps.pl) and -a (3ps.sg) are activated by a plural subject in content-based retrieval. As a result, both -a (3ps.sg) encoding [Number: Ø] and -ont (3ps.pl) encoding [Number: Plural] qualify for insertion candidacy in adherence to the Subset Principle of DM. The vocabulary items -a (3ps.sg) and -ont (3ps.pl) are, however, ordered by their information content. Their activation induces an information scale in which [Number: Ø] is less informative/specific than [Number: Plural] when the feature structure [Number: Plural] is activated by syntax. As a result, -ont (3ps.pl) wins as the most informative item in the set of activated candidates as -a (3ps.sg) is eliminated via a [–Plural] inference. In comparative selection of partially ordered vocabulary items, domain-general principles of scalar inference enable selection. In contrast, on our hypothesis, the detection that -ont constitues an error in a singular context does not involve domain-general scalar reasoning because -ont was never activated by the syntactic representation, contra NS. As we pointed out, scalar inferencing is well documented in the domains of implicatures and presuppositions in pragmatics, which crucially relies on lexical choice (Horn 1972; 1978; 1989; Heim 1991; Sauerland 2007). Scalar inferencing in the selection of vocabulary items addresses a long-standing domain-specific-domain-general syntax-lexis interaction in grammatical organization. As an anonymous reviewer points out, the claim of domain-generality of the processes involved in selection of the most informative vocabulary item constitutes a central hypothesis of our process-based implementation of the DM model. We take our experimental results as prima facie evidence for our process-based implementation of DM, which is open to further empirical testing. We note that grammatical construction benefits from an explicit focus on the processes needed to implement grammatical models.
The fact that a more robust response to ungrammaticality was obtained on (domain-general) picture-probe classifications associated with a compatible underspecified vocabulary item is we think highly suggestive of a domain-general item selection process. From the point of view of domain-specific processing, a stronger violation might be expected in the case of a violation involving an incompatible more specified vocabulary item. Indeed, Opitz et al. (2013) reported a strong Left Anterior Negativity effect due to a violation involving a more specific marker in German adjectival agreement. However, our different methodology addressing the potential interaction of vocabulary item selection for agreement morphemes with the classifications of probes linked to the ongoing construction of the sentence meaning revealed complementary patterns of processing load. Processing loads arose in the processing of errors involving underspecified vocabulary items, as the detection of these errors involved the focus of resources on the domain-general inferential processes involved in comparative vocabulary item selection. We believe therefore that the totality of the empirical evidence seems best explained in terms of the interaction of domain-specific access and domain-general processes of selection in vocabulary item retrieval. Violations involving the incompatibility of more specific morphology induce robust LANs for violations of domain-specific computations (Opitz et al. 2013), whereas violations involving underspecified morphology induce effects in general cognition as evidenced in our results.
5.2 Properties of externalization
We now examine how characteristics of French morphology might have influenced the results. The sound pattern of the French future tense morphology might play a part in determining aspects of lexical access and retrieval in a cohort. In this case, the future tense paradigm mangerai /mɑ̃ʒ(ə)ʁe/ eat.fut.1ps.sg, mangeras /mɑ̃ʒ(ə)ʁaZ/ eat.fut.2ps.sg, mangera /mɑ̃ʒ(ə)ʁa/ eat.fut.3ps.sg, mangerons /mɑ̃ʒəʁɔ̃Z/ eat.fut.1ps.pl, mangerez /mɑ̃ʒ(ə)ʁeZ/ eat.fut.2ps.pl, and mangeront /mɑ̃ʒ(ə)ʁɔ̃T/ eat.fut.3ps.pl for ‘will eat’ shows significant homophony. This homophony is disambiguated by spelling but only in rare cases of optional liaison in speech. Hence, from the point of view of a sound cohort, the sound [mɑ̃ʒ(ə)ʁa] either heard by the listener or internally generated by the reader would result in the additional activation of the affix –as (2ps.sg). Likewise, the sound [mɑ̃ʒ(ə)ʁɔ̃] either heard by the listener or internally generated by the reader would result in the additional activation of the affix –ons (1ps.pl). In word cohort activation, visual presentation should reduce the ambiguity of forms relative to aural presentation. However, distinct modalities should provide similar results given a feature-based morphosyntactic activation model. From the point of view of the Subset Principle and the grammatical organization that derives it, neither form mangeras /mɑ̃ʒ(ə)ʁaZ/ (eat.fut.2ps.sg) nor form mangerons /mɑ̃ʒəʁɔ̃Z/ (eat.fut.1ps.pl) will be activated in the process of externalization, because they include feature values Participant and Author absent from the syntactic computation. The results seem therefore confirmatory of feature-based lexical retrieval. We do not deny cohort activation based on sound structure, but we argue that it is not central in vocabulary item selection, as the main driver is feature structure.
Subject-verb agreement is a categorical rule in French, so that none of the errors presented in the stimuli is part of a native speaker’s input (or production), setting aside attraction errors in which the plural feature is recently activated. However, lexical frequency often affects processing. Singular verb forms are more frequent in the input than plural verb forms. A more frequent form is expected to be activated faster. Thus, in processing an inappropriate form, a more frequent form should be rejected more efficiently than a less frequent form, given different activation thresholds. In this case, the frequency of singular mangera (eat-fut.3ps.sg) should facilitate picture-probe classification relative to the plural form mangeront (eat-fut.3ps.pl). Hence, lexical frequency affects picture classification times in a direction that is contrary to the pattern observed in the study. Frequency thus should mitigate against the feature-based processing described above. The observed patterns seem therefore to highlight feature-based computations rather than relative frequency for singular and plural forms.
The amount of information to be maintained in memory also affects processing load. In terms of information load, faster recovery in ungrammatical conditions might be expected for lexical forms that carry less information, because they are less onerous to process, as observed in self-paced reading studies (e.g. Renaud 2010). Underspecified singular verb forms carry less information than specified plural verb forms in terms of their respective lexical specifications. The patterns that we have found do not seem to reflect information load. The observed effects seem therefore to highlight feature-based computations rather than the richness of information in vocabulary items.
5.3 Signatures of cognitive processes
We argued that vocabulary item retrieval involves both domain-specific syntactic computations determining access to subset vocabulary items and domain-general scalar reasoning applying to feature structure in real time in vocabulary item selection. This explains the interaction of subset/underspecified errors with picture-probe classifications, to the exclusion of superset errors. We argued that this constituted evidence for processes adhering to DM but against processes adhering to NS. It might be argued that our process-based cognitive modeling of DM and NS is incorrect, but this appears to leave the results unexplained. Indeed, in NS a vocabulary item specified for [Plural] competes with an underspecified singular item as part of the syntactic activation when the syntactic representation includes the singular. An underspecified singular vocabulary item does not compete with a vocabulary item specified for [Plural] when the syntactic representation includes [Plural]. This might suggest that externalizing an underspecified syntactic representation is more onerous. This does not appear to be supported in our results or in documented morphological error patterns in which underspecified morphological items typically substitute for more specified morphological items in child and adult acquisition (Ferdinand 1996; Prévost & White 2000; Herschensohn 2001; 2003).
In the absence of domain-general processes of inference in the comparative selection among partially ordered alternatives, the claim that the least costly form in a context requiring a more specified item induced the biggest effect might seem counterintuitive in view of the processing load relief provided by underspecified vocabulary items as pointed out by an anonymous reviewer. We concur that underspecified vocabulary items induce diminished load in terms of grammatical computing. On our proposal, underspecified vocabulary items induce additional costs to general cognition only in the comparative selection of the most informative alternative, when their coactivation interferes with the retrieval of the best match and they require elimination. Thus, underspecified vocabulary items are inserted in error in lieu of more specified vocabulary items when their inferred values failed to be maintained in the focus of attention. Hence, underspecification seems central to grammar precisely because it distributes processing load across subsystems. It saves on aspects of memory load given that lexical specifications have inherent memory costs, because specified values must reside in the focus of attention. If underspecification diminishes the cost of lexical storage and syntactic computations, it also enables the coactivation of multiple vocabulary items. This coactivation requires comparative selection, thereby shifting some of the cost of complex morphosyntactic processing to domain-general conceptual structure processing.
Hence, the underspecification of representations involved in vocabulary item selection allows different processes distributed across the subdomains of language. This is because the lesser cost of underspecification in the domain of morphosyntax is counterbalanced by the cost of default-value retrieval by inference in the domain of conceptual structure in support of lexical selection of the most informative item from a set of alternatives. Thus, reading-time asymmetries in mismatch generally seem to reflect feature-based insertion specifications in subset-based access to vocabulary by the syntactic derivation (Dekydtspotter & Renaud 2009; 2014; Renaud 2010). In contrast, increased classification times for picture probes after an underspecified vocabulary item crucially seem to reveal a hitherto hidden level of inferencing in vocabulary item selection. Our results suggest therefore that in processing a context for plural -ont, the computation activating <-ont, -a> distributes the cost of processing across domains in the elimination of alternatives.
6 Conclusion
Classification times for pictures probing the ongoing construction of the sentence meaning were significantly delayed as a third person singular future tense verb form such as mangera (eat-fut.3ps.sg) was computed as an inappropriate exponent for a syntactic node hosting a plural value. This did not arise as a third person plural future tense verb form such as mangeront (eat-fut.3ps.pl) was computed as inappropriate for a syntactic node without a plural value. These differences between these two types of error echo distinctions made under the Subset Principle of DM but not NS, whereby the insertion condition disallows the insertion of an overspecified third person plural future tense verb form such as mangeront (eat-fut.3ps.pl) in a singular context, and the selection criterion disallows the insertion of an underspecified third person singular future tense verb form such as mangera (eat-fut.3ps.sg) in a plural context. This claim must at this point be qualified by the limits of the experiment to the future tense. The effects found here should be more generally detectable. Our process-based implementation of DM offers a hypothesis for wider experimental verification. Despite these experimental limitations, the proposed implementation of vocabulary item retrieval in late insertion, in which vocabulary item retrieval implicates domain-specific computations and representations, as well as general inferential processes in conceptual structure offers a possible understanding of the interaction of grammar and general cognition.
We conclude therefore that vocabulary item retrieval can interact with the cognitive processes involved in generating the ongoing meaning of the sentence as the interaction of probe-classification times with the selection error shows. Crucially, an uninterpretable agreement feature on the verb cannot interact with conceptual structure processing based on the syntax-semantics interface, given that number agreement on the verb does not contribute to the interpretation. The conceptual representation generated by processing the verb was constant across verb forms. Any facilitation in picture classification times due to the close conceptual relation between the verb and the picture should therefore be the same across conditions. The interaction obtained was nonetheless based on form, when underspecified [Number: Ø] was fleshed out as [–Plural] via a real-time inference in a plural context, so that the resulting sentence was found to be ungrammatical. Inferential reasoning in vocabulary item selection thus seems to use processing resources that are also required for inferential processes in picture-probe classifications, enabling an interaction when additional processing capacity was required as in the case of error detection.
In sum, the evidence that we have gathered supports the view of a late-insertion model in which morphological knowledge is distributed across the components of grammar. The evidence that we have gathered also supports the view that morphological processing is distributed across domains, crucially involving the inferential system in the selection of the most informative alternative from a set of activated lexical items. The results match the contours of knowledge proposed by DM, in which vocabulary items may crucially be underspecified with respect to the syntactic information that they externalize, and the best item is selected. We have argued that these contours need not be stipulated but result from a specific psychologically plausible process-based mechanism of vocabulary item selection at the interface between domain-specific knowledge and general principles governing the representation of information in communication.
Appendix 1
Critical items and picture-probe to be classified16
-
Demain, l’enfant ne mangera [picture of a sandwich] pas beaucoup de desserts.
Tomorrow, the child will not eat a lot of desserts.
-
Dans trois semaines, l’employeur écrira [picture of a letter] très rapidement un rapport pour chaque employé.
In three weeks, the employer will write very quickly a report for each employee.
-
Le mois prochain, l’enseignant lira [picture of a book] avec beaucoup d’intérêt les devoirs des étudiants.
Next month, the teacher will read with a lot of inteest the students’ homework.
-
Lundi prochain, l’acteur ne boira [picture of a cup of coffee] pas beaucoup de jus d’orange.
Next Monday, the actor will not drink a lot of orange juice.
-
A partir de demain, l’étudiant ne conduira [picture of a car] pas très souvent la grande camionnette de l’université.
Starting with tomorrow, the student will not drive very often the big truck of the university.
-
La semaine prochaine, l’invité offrira [picture of flowers] un peu trop de cadeaux aux enfants.
Next week, the guest will offer a little too many presents to the children.
-
Mercredi prochain, l’organisateur ne servira [picture of a meal] pas du tout d’alcool à la fête organisée par le département.
Next Wednesday, the organizer will not serve any alcohol at the party organized by the department.
-
Dans un mois, l’ami ouvrira [picture of a door] sans trop de difficultés un compte bancaire une fois la promotion reçue.
In a month, the friend will open without too many difficulties a bank account once the promotion is received.
-
Jeudi prochain, l’assistant fermera [picture of a window] sans aucune explication la salle de conférence de l’entreprise.
Next Thursday, the assitant will close without any explanation the conference room of the company.
-
Dans quelques semaines, l’artiste paiera [picture of money] avec beaucoup de difficulté la dette accumulée depuis des années.
In a few weeks, the artist will pay with a lot of difficulty the debt accumulated over the years.
Appendix 2
Average log RTs by item for each condition in both modalities combined across all subjects (C1 – Singular verb form error; C2 – Plural verb form agreement; C3 – Plural verb form error; C4 – Singular verb form agreement)17
| Item 1 | C1 | 2.8336 | |
| C2 | 2.8124 | ||
| C3 | 2.8229 | ||
| C4 | 2.8227 | ||
| Item 2 | C1 | 2.8668 | |
| C2 | 2.8553 | ||
| C3 | 2.8355 | ||
| C4 | 2.8346 | ||
| Item 3 | C1 | 2.8317 | |
| C2 | 2.8164 | ||
| C3 | 2.8290 | ||
| C4 | 2.8053 | ||
| Item 4 | C1 | 2.8470 | |
| C2 | 2.8350 | ||
| C3 | 2.8270 | ||
| C4 | 2.8423 | ||
| Item 5 | C1 | 2.8563 | |
| C2 | 2.8295 | ||
| C3 | 2.8195 | ||
| C4 | 2.8114 | ||
| Item 6 | C1 | 2.8463 | |
| C2 | 2.8452 | ||
| C3 | 2.8377 | ||
| C4 | 2.8371 | ||
| Item 7 | C1 | 2.8818 | |
| C2 | 2.8341 | ||
| C3 | 2.8510 | ||
| C4 | 2.7993 | ||
| Item 8 | C1 | 2.8553 | |
| C2 | 2.8289 | ||
| C3 | 2.8424 | ||
| C4 | 2.8108 | ||
| Item 9 | C1 | 2.8490 | |
| C2 | 2.8213 | ||
| C3 | 2.8561 | ||
| C4 | 2.8261 | ||
| Item 10 | C1 | 2.8485 | |
| C2 | 2.8042 | ||
| C3 | 2.8292 | ||
| C4 | 2.8050 | ||
Acknowledgements
We would like to thank our participants for volunteering to be part of this study. We would also like to thank the anonymous reviewers for their insightful comments.
Notes
- As pointed by an anonymous reviewer, Harbour (2007; 2011; 2014) argues that a privative number feature system is not tenable for the semantic representation of number. Harbour’s argument relies on a semantic treatment of number in which the singular is [+atomic] and the plural is [–atomic]. However, the plural may well include atoms, given that No dogs barked entails No dog barked (Schwarzschild 1996). For our part, we assume that the semantics of the feature [Plural] involves an operation of sum/collection formation yielding a part structure (atomic semilattice), following Link (1983) among many others. This operation applies to domains of basic atomic entities: the singular. The Plural denotes a domain that includes both the sums/collections and the atoms. Hence, semantically, the singular domain of basic entities constitutes a subset of the plural domain. As a result, the singular is presuppositionally stronger than the plural (Sauerland 2007) so that the [–atomic] feature of the plural is obtained by a scalar inference in relation to the basic singular domain. The case of number in grammar and semantics therefore strongly illustrates the significance of information scales across domains. [^]
- Halle (1997) argued that the 3rd person constitutes a default value. This is because 3rd person vocabulary items involve the feature Person with no further specifications. 2nd person vocabulary items are informationally stronger, involving the representation Person: Participant with no further specification. 1st person vocabulary items are even more specified, involving the feature structure Person: Participant: Author. [^]
- Heim (1991) formulates this for presuppositions. [^]
- As pointed out by an anonymous reviewer, one may wonder whether the singular is always interpreted as [–Plural], which would create the counter-intuitive situation in which processing the singular seems to always bring about additional costs. Crucially, when there is no information scale, then no scalar inference arises since scalar inferences are dependent on an information scale. Thus, when the syntactic structure only coactivates a singular (underspecified) vocabulary item, there is no need to flesh it out in item selection (e.g. a grammatical item such as L’enfant mangera). [^]
- As an anonymous reviewer points out, different event-related potential responses for compatibility vs. specificity (incompatibility) violations (see Opitz et al. 2013) resulting in a strong Left Anterior Negativity (LAN) effect linked to a violation involving a specific marker need not include a cognitive division between domain-specific access and domain-general selection. The domain-specific access vs. domain-general selection constitutes an additional (theoretically grounded) assumption which can be experimentally tested. We note, however, that robust LAN effects for a specific marker as discussed by Opitz et al. (2013) is compatible with our claims, since the LAN indexes a syntax-related/domain-specific access violation. [^]
- The future tense paradigm in French: mangerai /mɑ̃ʒ(ə)ʁe/ eat.fut.1ps.sg, mangeras /mɑ̃ʒ(ə)ʁaZ/ eat.fut.2ps.sg, mangera /mɑ̃ʒ(ə)ʁa/ eat.fut.3ps.sg mangerons /mɑ̃ʒəʁɔ̃Z/, eat.fut.1ps.pl, mangerez /mɑ̃ʒ(ə)ʁeZ/ eat.fut.2ps.pl and mangeront /mɑ̃ʒ(ə)ʁɔ̃T/eat.fut.3ps.pl for ‘will eat’. [^]
- There might be additional activation of the affixes –as (2ps.sg) and –ont (1ps.pl) through phonology in listening, self-generated speech, or reading, but such phonological activations are unrelated to feature structure and should not play a role in our investigation. [^]
- The feature Number on the verb is uninterpretable. It does not contribute to the interpretation of the verb (as opposed to the interpretation of an NP, for example). [^]
- It is of course possible to envisage a situation in which the participants would retrieve the lexical item for the picture to be classified and thus subvocalize picture classification. Crucially, when reading aloud or listening to the items, none of the participants vocalized any picture classification. The tasks were also quite demanding to ensure processing pressure, which would also deter participants from subvocalizing either the object seen in the picture, or the decisions on classifications. Crucially, the participants were asked to classify the pictures using the keyboard, as explained below. [^]
- The longer time for plural form presentation reflects the fact that they involve two additional consonants in the written, and a typically lengthened nasal vowel in the aural stimuli. [^]
- An anonymous reviewer wonders if the results would hold or provide an even stronger case for a more abstract general-domain task (e.g. categorizing color or shape). Our current design builds on the language as meaning with externalization. How far into general cognition could an effect be found constitutes a significant point, once an effect is found in the construction of the sentence meaning. We entertained this issue in the experiment development phase and opted for the approach targeting the local construction of the sentence meaning on first pass since an unexpected probe might wipe out very subtle effect due to the inference. We leave this effect on categorization of unrelated probes for further research. [^]
- Also, see Hopp (2010), Miller (2014) for L1 and L2 among many others for the use of ANOVAs in statistical analysis of behavioral data. [^]
- A repeated measures ANOVA with singular and plural d’ values as dependent variables and modality as within-subjects factor revealed no statistically significant effects, given the standard deviations. [^]
- No interaction form*d’-difference was found, F(1,35) = 2.291, p = 0.282, ηp2 = 0.033. No interaction grammaticality*d’-difference was found either, F(1,35) = 0.407, p = 0.528, ηp2 = 0.011. An interaction form*grammaticality*d’-difference did not reach significance, F(1,35) = 3.872, p = 0.057, ηp2 = 0.1. [^]
- No interaction grammaticality*modality was found, F(1,35) = 2.020, p = 0.164, ηp2 = 0.055. No interaction form*grammaticality*modality was found either, F(1,35) = 1.281, p = 0.265, ηp2 = 0.035. [^]
- Each item was presented in four conditions, by manipulating the number on the subject and the verb and obtaining two grammatical and two ungrammatical items. For space reasons, the Appendix presents one condition per item where both the verb and the subject are in singular. [^]
- In bold, the condition that took longest for each item. For 9/10 items, C1 took the longest, as expected. [^]
Competing Interests
The authors declare that they have no competing interests.
References
Ackema, Peter & Neeleman, Ad. 2004. Beyond morphology: Interface conditions on word formation. Oxford: Oxford University Press. DOI: http://doi.org/10.1093/acprof:oso/9780199267286.001.0001
Anderson, Stephen R. 1969. West Scandinavian vowel systems and the ordering of phonological rules. Doctoral dissertation: Massachusetts Institutes of Technology.
Baker, Mark C. 1988. Incorporation: A theory of grammatical function changing. Chicago: University of Chicago Press.
Berwick, Robert C. & Chomsky, Noam. 2016. Why only us: Language and evolution. Cambridge, MA: MIT Press. DOI: http://doi.org/10.7551/mitpress/9780262034241.001.0001
Bock, J. Kathryn & Miller, Carol A. 1991. Broken agreement. Cognitive psychology 23(1). 45–93. DOI: http://doi.org/10.1016/0010-0285(91)90003-7
Bobaljik, Jonathan. 2017. Distributed morphology. Oxford Research Encyclopedia of Linguistics. DOI: http://doi.org/10.1093/acrefore/9780199384655.013.131
Chanquoy, Lucille & Negro, Isabelle. 1996. Subject-verb agreement errors in written productions: A study of French children and adults. Journal of Psycholinguistic Research 25(5). 553–570. DOI: http://doi.org/10.1007/BF01758183
Dekydtspotter, Laurent & Farmer, Kelly. 2016. On the processing of subject clefts in English-French interlanguage: Parsing to learn and the subject relativizer qui. In Guijarro-Fuentes, Pedro & Schmitz, Katrin & Müller, Natasha (eds.), The acquisition of French in multilingual contexts, 66–93. Bristol, England: Multilingual Matters. DOI: http://doi.org/10.21832/9781783094530-006
Dekydtspotter, Laurent & Miller, A. Katherine. 2013. Inhibitive and facilitative priming induced by traces in the processing of wh-dependencies in a second language. Second Language Research 29(3). 345–372. DOI: http://doi.org/10.1177/0267658312467030
Dekydtspotter, Laurent & Renaud, Claire. 2009. On the contrastive analysis of features in second language acquisition: Uninterpretable gender on past participles in English-French processing. Second Language Research 25(2). 255–267. DOI: http://doi.org/10.1177/0267658308100287
Embick, David & Noyer, Rolf. 2007. Distributed morphology and the syntax/morphology interface. In Ramchand, Gillian & Reiss, Charles (eds.), The Oxford handbook of linguistic interfaces, 289–324. Oxford: Oxford University Press. DOI: http://doi.org/10.1093/oxfordhb/9780199247455.013.0010
Felser, Claudia & Roberts, Leah. 2007. Processing wh-dependencies in a second language: A cross-modal priming study. Second Language Research 23(1). 9–36. DOI: http://doi.org/10.1177/0267658307071600
Ferdinand, Astrid. 1996. The development of functional categories: The acquisition of the subject in French. The Hague: Holland Academic Graphics.
Forster, Kenneth I. & Forster, Jonathan C. 2003. DMDX: A Windows display program with millisecond accuracy. Behavior Research Methods 35(1). 116–124. DOI: http://doi.org/10.3758/BF03195503
Franck, Julie & Vigliocco, Gabriella & Nicol, Janet. 2002. Subject-verb agreement errors in French and English: The role of syntactic hierarchy. Language and Cognitive Processes 17(4). 371–404. DOI: http://doi.org/10.1080/01690960143000254
Grice, H. Paul. 1975. Logic and conversation. In Cole, Peter & Morgan, Jerry L. (eds.), Speech acts: Syntax and semantics 3. 41–58. New York: Academic Press.
Halle, Morris. 1997. Distributed Morphology: Impoverishment and Fission. MIT Working Papers in Linguistics 30. 425–449.
Halle, Morris & Marantz, Alec. 1993. Distributed morphology and the pieces of inflection. In Hale, Ken & Keyser, Samuel J. (eds.), The view from building 20: Essays on linguistics in honor of Sylvain Bromberger, 111–176. Cambridge, MA: MIT Press.
Harbour, Daniel. 2007. Morphosemantic number: From Kiowa noun classes to UG number features. Dordrecht: Springer. DOI: http://doi.org/10.1007/978-1-4020-5038-1
Harbour, Daniel. 2011. Valence and atomic number. Linguistic Inquiry 42(4). 561–594. DOI: http://doi.org/10.1162/LING_a_00061
Harbour, Daniel. 2014. Paucity, Abundance, and the Theory of number. Language 90(1). 185–229. DOI: http://doi.org/10.1353/lan.2014.0003
Heim, Irene. 1991. Artikel und Definitheit [Articles and definiteness]. In von Stechow, Arnim & Wunderlich, Dieter (eds.), Semantik: Ein internationales Handbuch der zeitgenössischen Forschung, 487–535. Berlin: de Gruyter. DOI: http://doi.org/10.1515/9783110126969.7.487
Herschensohn, Julia. 2001. Missing inflection in second language French: Accidental infinitives and other verbal deficits. Second Language Research 17(3). 273–305. DOI: http://doi.org/10.1177/026765830101700303
Herschensohn, Julia. 2003. Verbs and rules: Two profiles of French morphology acquisition. French Language Studies 4. 23–45. DOI: http://doi.org/10.1017/S0959269503001030
Hopp, Holger. 2010. Ultimate attainment in L2 inflection: Performance similarities between non-native and native speakers. Lingua 120(4). 901–931. DOI: http://doi.org/10.1016/j.lingua.2009.06.004
Horn, Laurence. 1972. On the semantic properties of logical operators in English. Los Angeles: University of California dissertation.
Horn, Laurence. 1978. Lexical incorporation, implicature and the least effort hypothesis. In Farkas, Donka & Jacobsen, Wesley M. & Todrys, Karol W. (eds.), Papers from the parasession on the lexicon, 196–209. Chicago: Chicago Linguistic Society.
Horn, Laurence. 1989. A natural history of negation. Chicago: The University of Chicago Press.
Kiparsky, Paul. 1973. “Elsewhere” in phonology. In Anderson, Stephen & Kiparsky, Paul (eds.), A festshrift for Morris Halle, 93–106. New York: Holt, Rinehart and Winston.
Kornfilt, Jaklin & Whitman, John. 2011. Afterword: Nominalizations in syntactic theory. Lingua 121(7). 1297–1313. DOI: http://doi.org/10.1016/j.lingua.2011.01.008
Lasnik, Howard. 1995. Verbal morphology: Syntactic structures meets the minimalist program. In Campos, Héctor & Kempchinsky, Paula (eds.). Evolution and revolution in linguistic theory: Studies in honor of Carlos P. Otero, 251–275. Washington D.C.: Georgetown University Press.
Li, Yafei. 1990. On VV compounds in Chinese. Natural Language & Linguistic Theory 8(2). 177–207. DOI: http://doi.org/10.1007/BF00208523
Link, Godehard. 1983. The logical analysis of plurals and mass terms: A lattice-theoretical approach. In Portner, Paul & Partee, Barbara H. (eds.), Formal semantics: The essential readings, 127–146. Blackwell Publishing. DOI: http://doi.org/10.1002/9780470758335.ch4
López Prego, Beatriz & Gabriele, Alison. 2014. Examining the impact of task demands on morphological variability in native and non-native Spanish. Linguistic Approaches to Bilingualism 4(2). 192–221. DOI: http://doi.org/10.1075/lab.4.2.03lop
Love, Tracy E. 2007. The processing of non-canonically ordered constituents in long distance dependencies by pre-school children: A real-time investigation. Journal of Psycholinguistic Research 36(3). 191–206. DOI: http://doi.org/10.1007/s10936-006-9040-9
Macmillan, Neil A. & Creelman, C. Douglas. 1991. Detection theory: A user’s guide. New York: Cambridge University Press.
Marantz, Alec. 1997. No escape from syntax: Don’t try morphological analysis in the privacy of your own lexicon. University of Pennsylvania Working Papers in Linguistics 4(2). 201–255.
McDonald, Janet L. 2006. Beyond the critical period: Processing-based explanations for poor grammaticality judgment performance by late second language learners. Journal of Memory and Language 55(3). 381–401. DOI: http://doi.org/10.1016/j.jml.2006.06.006
Miller, A. Katherine. 2014. Accessing and maintaining referents in L2 processing of wh-dependencies. Linguistics Approaches to Bilingualism 4(2). 167–191. DOI: http://doi.org/10.1075/lab.4.2.02mil
Miller, A. Katherine. 2015. Facilitating the task for second language processing research: A comparison of two testing paradigms. Applied Psycholinguistics 36(3). 613–637. DOI: http://doi.org/10.1017/S0142716413000362
Nicol, Janet L. & Forster, Kenneth I. & Veres, Csaba. 1997. Subject-verb agreement processes in comprehension. Journal of Memory and Language 36(4). 569–587. DOI: http://doi.org/10.1006/jmla.1996.2497
Opitz, Andreas & Regel, Stefanie & Müller, Gereon & Friederici, Angela D. 2013. Neurophysiological evidence for morphological underspecification in German strong adjective inflection. Language 89(2). 231–264. DOI: http://doi.org/10.1353/lan.2013.0033
Pearlmutter, Neal J. & Garnsey, Susan M. & Bock, Kathryn. 1999. Agreement processes in sentence comprehension. Journal of Memory and Language 41(3). 427–456. DOI: http://doi.org/10.1006/jmla.1999.2653
Pollock, Jean-Yves. 1989. Verb movement, universal grammar and the structure of IP. Linguistic Inquiry 20(3). 365–424.
Prévost, Philippe & White, Lydia. 2000. Missing surface inflection hypothesis or impairment in second language acquisition? Evidence from tense and agreement. Second Language Research 16(2). 103–133.
Renaud, Claire. 2010. On the nature of agreement in English-French acquisition: A processing investigation in the verbal and nominal domains. Bloomington, IN: Indiana University dissertation.
Roberts, Leah & Marinis, Theodore & Felser, Claudia & Clahsen, Harald. 2007. Antecedent priming at trace positions in children’s sentence processing. Journal of Psycholinguistic Research 36(2). 175–188. DOI: http://doi.org/10.1007/s10936-006-9038-3
Sauerland, Uli. 2007. Implicated presuppositions. In Steube, Anita (ed.), Sentence and context, 1–28. Berlin: Mouton de Gruyter.
Schwarzschild, Roger. 1996. Pluralities. Kluwer, Dordrecht. DOI: http://doi.org/10.1007/978-94-017-2704-4
Starke, Michal. 2010. Nanosyntax: A short primer to a new approach to language. Nordlyd 36(1). 1–6. DOI: http://doi.org/10.7557/12.213
Starke, Michal. 2018. Complex left branches, spellout and prefixes. In Baunaz, Lena & De Clercq, Karen & Haegeman, Liliane & Lander, Eric (eds.), Exploring nanosyntax, 239–249. Oxford: Oxford University Press. DOI: http://doi.org/10.1093/oso/9780190876746.003.0009
Svenonius, Peter. 2012. Spanning. https://ling.auf.net/lingbuzz/001501
Tranel, Bernard. 1996. French liaison and elision revisited: A unified account within optimality theory. Aspects of Romance linguistics, 433–455.
Traxler, Matthew J. 2011. Introduction to psycholinguistics: Understanding language science. Chicester, UK: Wiley-Blackwell.
Wagers, Matthew W. & Lau, Ellen F. & Phillips, Colin. 2009. Agreement attraction in comprehension: Representations and processes. Journal of Memory and Language 61(2). 206–237. DOI: http://doi.org/10.1016/j.jml.2009.04.002
Wagers, Matthew W. & McElree, Brian. 2011. Memory for linguistics features and the focus of attention: Evidence for the dynamics of agreement. Unpublished Manuscript, University of California Santa Cruz and New York University.